Compressione di immagini basata su DCT |
|
Tra tutte le varianti della compressione basata su trasformata coseno, quella più comunemente incontrata in pratica si basa sull'algoritmo che segue.
(1) Detta f(m,n) la matrice in cui sono organizzati i campioni di
un'immagine da MxN pixel, la matrice viene suddivisa in 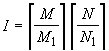 blocchi da M1xN1
pixel (solitamente è M1 = N1 =
8, ma non è raro trovare utilizzati anche altri valori), e sia fi(m,n)
la matrice corrispondente a ciascun blocco.
blocchi da M1xN1
pixel (solitamente è M1 = N1 =
8, ma non è raro trovare utilizzati anche altri valori), e sia fi(m,n)
la matrice corrispondente a ciascun blocco.
(2) Viene calcolata la trasformata coseno discreta (discrete cosine transform, DCT) di ciascun blocco fi(m,n):
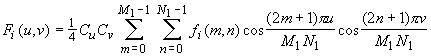
dove
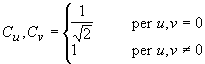
(3) Ciascuna matrice Fi(u,v) di coefficienti DCT viene uniformemente quantizzata mediante divisione elemento per elemento per una tavola di quantizzazione Qi(u,v):
![]()
dove rnd[ ] è la funzione di arrotondamento. Le tavole di quantizzazione Qi(u,v) possono essere tutte e sempre identiche tra di loro, ovvero possono essere rese funzione dell'immagine f(m,n) o addirittura della matrice fi(m,n), nel qual caso la compressione si dice adattativa. È importante osservare che la scelta delle tavole di quantizzazione determina il fattore di compressione finale.
(4) Dopo la quantizzazione, e in preparazione per la codifica entropica, ciascun coefficiente Ei(0,0) (che viene detto coefficiente DC, e rappresenta la componente in continua del blocco i-esimo) viene trattato separatamente dagli altri coefficienti del blocco (detti coefficienti AC), e viene codificato in modo differenziale secondo la relazione
E'i(0,0) = Ei(0,0) – Ei–1(0,0)
avendo posto E–1(0,0) = 0.
(5) Dopo la quantizzazione, e in preparazione per la codifica entropica, i coefficienti della matrice Ei(u,v) vengono organizzati in un vettore ei. Il meccanismo di scansione della matrice per il riordinamento dei coefficienti è solitamente quello detto a zig-zag:
ei = [ E'i(0,0) Ei(0,1) Ei(1,0) Ei(2,0) Ei(1,1) Ei(0,2) Ei(0,3) ... Ei(M1–1, N1–1) ]T
(6) A ciascuno dei vettori ei così ottenuti viene applicata una codifica entropica senza perdite (lossless). Le due codifiche entropiche più sovente utilizzate sono la codifica di Huffman e la codifica aritmetica. Stanti le diverse proprietà statistiche dei coefficienti DC e dei coefficienti AC, è comunemente invalsa nell'uso la pratica di utilizzare tavole di codifica distinte per ciascuna delle due classi di coefficienti.
(7) Il risultato della codifica entropica dei vettori ei, eventualmente completato con opportune informazioni di servizio (dimensione dei blocchi, tipo di codifica entropica utilizzata, etc.), costituisce infine il risultato della compressione dell'immagine originale f(m,n).
Il processo di decompressione segue essenzialmente l'ordine inverso a quello di compressione:
(8) Dopo eliminazione delle informazioni di servizio citate al passo (7), vengono ricostruiti i vettori ei, e da questi le matrici Ei(u,v).
(9) L'applicazione delle tavole di quantizzazione citate al passo (3) viene compensata mediante l'operazione
Gi(u,v) = Ei(u,v) Qi(u,v)
(10) Ciascuna matrice Gi(u,v) viene sottoposta alla trasformata coseno discreta inversa:
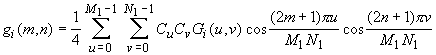
(11) Le singole matrici gi(m,n) vengono ricomposte in modo da ricostruire una matrice g(m,n) avente le stesse dimensioni della matrice originale f(m,n).
Naturalmente, per via della imperfetta corrispondenza tra la quantizzazione del passo (3) e la dequantizzazione del passo (9), la matrice g(m,n) ottenuta in decodifica non è identica all'originale f(m,n) ma è affetta da errori che possono essere sinteticamente descritti in termini di rapporto segnale-rumore:
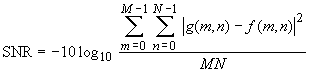
Tale valore risulta assai utile, in fase di valutazione delle prestazioni dell'algoritmo di compressione, per quantificare la fedeltà dell'immagine recuperata rispetto all'immagine originale.
La procedura descritta, sebbene valida solo per immagini costituite da una sola componente (ad esempio, immagini a livelli di grigio), è tuttavia facilmente estendibile ad immagini costituite da più componenti (ad esempio, immagini a colori o multispettrali). Nel caso di immagini costituite dalle tre componenti standard di colore rosso (R), verde (G), blu (B) è pratica comune trasformare le tre matrici corrispondenti f(R)(m,n), f(G)(m,n), f(B)(m,n) in altrettante matrici f(Y)(m,n), f(U)(m,n), f(V)(m,n) definite come segue (trasformazione RGB-YUV):

Un accorgimento molto usato in pratica, col quale si sfruttano determinate caratteristiche di sensibilità cromatica del sistema visivo umano al fine di aumentare i fattori di compressione conseguibili, consiste nel lasciare immutata la matrice f(Y)(m,n) (componente di luminanza) e nel sottocampionare le matrici f(U)(m,n), f(V)(m,n) (componenti di crominanza); i fattori di sottocampionamento comunemente utilizzati vanno da 2:1 ad 8:1. In fase di decodifica dell'immagine, le componenti di crominanza vengono sovracampionate del medesimo fattore prima dell'applicazione della trasformazione inversa con la quale si ricavano le matrici finali g(R)(m,n), g(G)(m,n), g(B)(m,n) mediante le quali viene ricostruita l'immagine decodificata.
|
|||||||
© 1997-2003 Paolo Marincola (Rome, Italy)
e-mail: pmaNOSPAM@acm.org (eliminare
i caratteri "NOSPAM" per ottenere l'indirizzo esatto)
Commenti, osservazioni e suggerimenti sono estremamente graditi.
Last revised: 2003-12-06 19:37