Introduzione all'architettura dei calcolatori |
|
La maggior parte dei modelli computazionali che si discostano da quello appena
descritto hanno come obiettivo quello di conseguire il massimo adattamento possibile tra
l'organizzazione delle unità funzionali e la struttura intrinseca di una varietà di
algoritmi. Possiamo di fatto ricorrere a tre meccanismi fondamentali per aumentare
l'efficienza di una macchina di von Neumann:
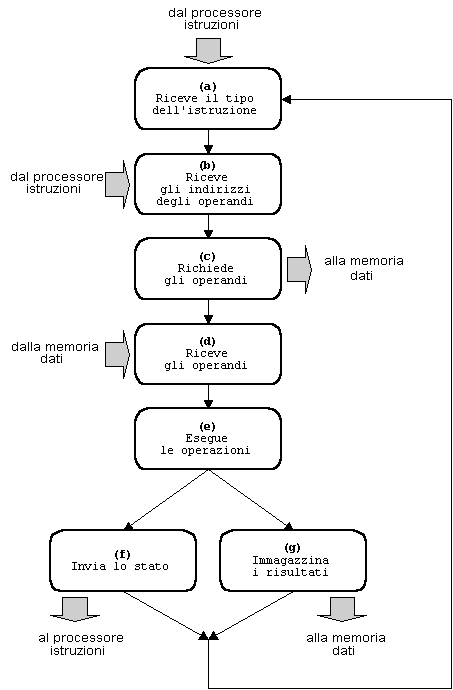
La ristrutturazione del diagramma di stato non produce in realtà nuove classi di architetture, perché si traduce essenzialmente in modi diversi di implementare le medesime operazioni. Nel processore di dati, ad esempio, l'invio delle informazioni di stato al processore di istruzioni (fase f) e l'immagazzinamento dei risultati nella memoria dati (fase g) sono operazioni indipendenti, che possono dunque avvenire simultaneamente. Il diagramma di stato del processore di dati può allora essere riorganizzato come in Fig. 7:
|
||
|
se Tf e Tg sono i tempi necessari all'esecuzione delle singole fasi f e g, il tempo necessario perché entrambe le fasi siano completate non è più Tf + Tg, come nel diagramma di Fig. 5, ma diventa pari al massimo tra i due valori Tf e Tg, con una corrispondente riduzione del tempo totale di esecuzione del ciclo.
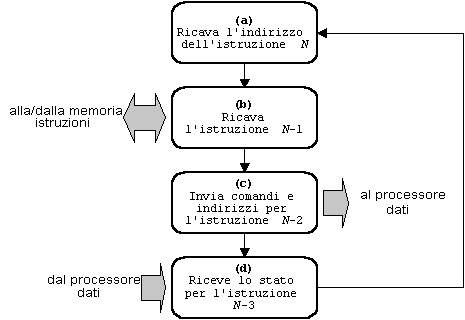
Con la seconda tecnica, detta pipelining, si ammette che in un dato istante il diagramma di stato possa prevedere più di uno stato attivo su dati appartenenti a istruzioni distinte. Consideriamo il diagramma semplificato di un processore di istruzioni, rappresentato in Fig. 8;
|
||
|
quando il processore ha finito di ricavare l'indirizzo della k-esima istruzione di un programma (fase a), viene attivata la fase b che provvede a estrarre l'istruzione dalla memoria. Se la struttura fosse simile a quelle viste finora, il blocco hardware che provvede alla fase a resterebbe inattivo fino a che l'intero ciclo di istruzione non venga portato a compimento; in una struttura pipeline, invece, la fase a può immediatamente essere riattivata in maniera da ricavare l'indirizzo dell'istruzione successiva (la (k+1)-esima nel programma). In maniera analoga, quando lo stato c diventa attivo sulla k-esima istruzione per inviare al processore di dati le informazioni ad essa relative, lo stato b viene riattivato per estrarre la (k+1)-esima istruzione dalla memoria, e lo stato a può essere ulteriormente riattivato per ricavare l'indirizzo della (k+2)-esima istruzione. Nella Fig. 8 è raffigurato lo stato del processore di istruzioni nell'istante in cui tutte e quattro le fasi a, b, c, d sono simultaneamente attive rispettivamente sulle istruzioni N, N-1, N-2 e N-3. Si noti anche come il diagramma presupponga un certo grado di pipelining anche nel processore di dati: esso deve infatti essere in grado di ricevere comandi e indirizzi relativi all'istruzione N-2 e, nel medesimo istante, di trasmettere le informazioni di stato relative all'istruzione N-3.
Se n è il numero delle fasi in un diagramma di stato, e se t è il tempo richiesto per l'esecuzione di ciascuna fase (1), allora il tempo totale di esecuzione di un ciclo completo è nt, e la velocità media di esecuzione delle istruzioni, cioè il numero di istruzioni eseguite nell'unità di tempo, è 1/nt. Se permettiamo che n stati distinti siano simultaneamente attivi nel diagramma, uno per ciascuna fase, ciò significa che stiamo rappresentando n differenti istruzioni, ciascuna in un diverso stato di avanzamento. Il tempo richiesto per l'esecuzione completa di una singola istruzione è ancora nt, poiché i dati relativi ad una singola istruzione devono ovviamente attraversare tutte le n fasi, ma la velocità media diventa adesso 1/t, con un miglioramento di n volte rispetto alla stessa struttura priva di pipeline.
Ci sono naturalmente difficoltà pratiche nella realizzazione di questo schema; potremmo mostrare, ad esempio, come l'esecuzione di certe particolari istruzioni (istruzioni di salto e simili) deve necessariamente interrompere il flusso continuo di attività da una fase all'altra. Le prestazioni di una struttura a pipeline, tuttavia, sono in generale notevolmente superiori a quelle della macchina base di von Neumann. Non è fuor di luogo tuttavia sottolineare come l'impiego del pipelining non comporti l'introduzione di nuove unità funzionali, ma richieda soltanto una opportuna implementazione di quelle già esistenti; potremo perciò classificare le unità funzionali in due tipi: semplici ovvero a pipeline.
La terza tecnica rivolta ad accrescere le prestazioni di un sistema consiste nel replicare le unità funzionali, facendole operare in parallelo. Questo processo, applicato alla struttura base della macchina di von Neumann, produce diverse architetture alternative; cominceremo qui con i casi più semplici, che conducono ai processori vettoriali (detti anche array processors).
Un processore vettoriale è una macchina astratta dotata di un processore di istruzioni, una memoria istruzioni, un insieme di processori di dati e un insieme di memorie dati. Quando il processore di istruzioni invia un comando per l'esecuzione di un'operazione, questo viene ricevuto in parallelo da tutti i processori di dati, che eseguono simultaneamente le operazioni richieste su operandi distinti residenti nelle memorie dati. Per di più, è ammessa la possibilità che i processori di dati comunichino tra di loro.
In un'architettura dotata di unità funzionali multiple è ovviamente necessario
descrivere il modo in cui esse possono essere collegate tra di loro; queste connessioni,
visualizzate qui mediante commutatori astratti, possono nella realtà essere implementate
con una grande varietà di tecniche (bus, commutatori dinamici, reti statiche di
interconnessione, e così via). Possiamo pensare di utilizzare le seguenti forme di
commutatori astratti:
In tutti i processori vettoriali è presente un commutatore 1:N che provvede a connettere l'unico processore di istruzioni ai vari processori di dati. Possiamo tuttavia classificare i processori vettoriali in famiglie in base al tipo di commutatore usato per interconnettere i processori di dati con le memorie dati.
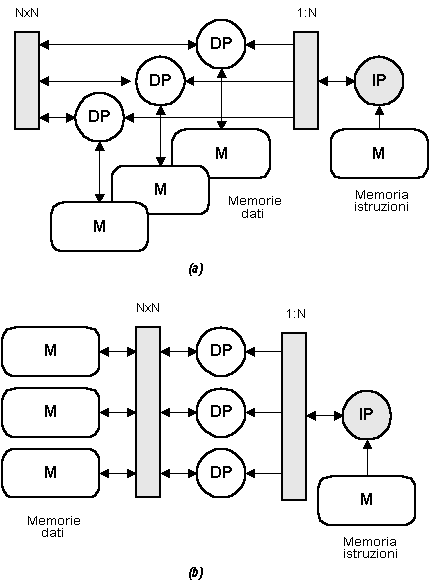
Una prima famiglia, illustrata in Fig. 9a, prevede una connessione N:N tra processori di dati e memorie dati, e una connessione NxN tra processori di dati. Questo schema di interconnessione si trova realizzato in un calcolatore chiamato Connection Machine, che impiega 65536 processori di dati divisi in 4 grandi gruppi [10] [21]. In una seconda famiglia, illustrata in Fig. 9b, i processori di dati sono connessi alle memorie dati attraverso un commutatore NxN, mentre non c'è alcuna interconnessione tra i processori di dati.
|
||
|
I processori vettoriali sono così chiamati perché la loro efficienza è massima su dati di tipo vettoriale, nei quali una stessa operazione deve essere replicata tante volte quante sono le componenti dei vettori operandi; in una struttura come quelle appena viste, il processore di istruzioni decodifica una sola istruzione, e i processori di dati operano ciascuno su una singola componente degli operandi: il parallelismo dei processori di dati fa allora sì che un gran numero di componenti vengano elaborate in un unico ciclo di istruzione.
I problemi legati ai processori vettoriali sono essenzialmente legati da una parte all'esigenza di evidenziare, a livello di programma, il parallelismo intrinseco nei dati del problema -- compito spesso arduo, da cui la tecnologia dei compilatori tende sempre più a sollevare il programmatore --, e dall'altro alla gestione delle comunicazioni tra le varie unità funzionali. Vedremo più avanti come, all'aumentare del numero di unità funzionali, aumenti di pari passo il numero di possibili interconnessioni.
Il concetto di processore vettoriale si basa sull'assunto che una certa quantità di dati possa essere manipolata allo stesso modo nel medesimo istante. Tuttavia, molti problemi non si adattano a sufficienza a questo schema, ed appare quindi naturale replicare, oltre al processore di dati, anche il processore di istruzioni, dando in tal modo origine ad una molteplicità di threads (flussi) simultanei di controllo. Questo approccio conduce alle macchine di von Neumann parallele, che si differenziano a loro volta in due famiglie di architetture chiamate rispettivamente ad accoppiamento stretto e ad accoppiamento lasco.
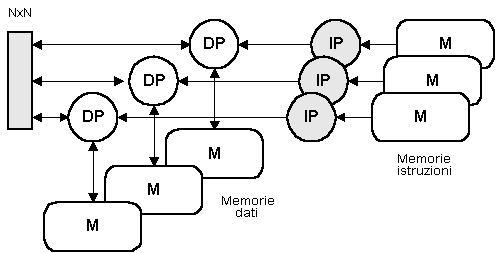
In un sistema ad accoppiamento stretto vengono replicati sia il processore di istruzioni, sia il processore di dati, sia la memoria dati; i processori di dati, però, sono connessi alle memorie attraverso un commutatore NxN, in modo che ciascun processore abbia la possibilità di accedere indifferentemente a ciascuna memoria (Fig. 10); le memorie dati, qui rappresentate come unità funzionali indipendenti, possono trovarsi in taluni casi riunite in un'unica unità funzionale.
|
||
|
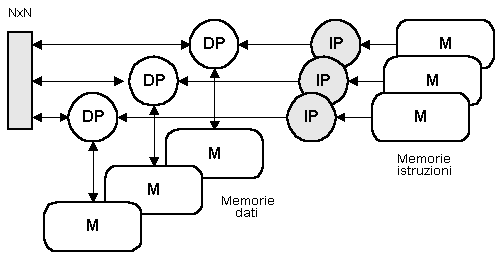
Un sistema ad accoppiamento lasco (Fig. 11) è simile al precedente, con l'unica sostanziale differenza che i processori di dati sono connessi alle memorie mediante un commutatore N:N, affinché ciascun processore abbia accesso ad una sua memoria "privata"); i processori di dati, inoltre, sono interconnessi tra loro mediante un commutatore NxN, al fine di potersi scambiare informazioni nella maniera di volta in volta più opportuna.
|
||
|
I problemi inerenti a questo tipo di architetture sono ovviamente quelli stessi dei processori vettoriali, con in più la difficoltà di adattare, strutturare e segmentare gli algoritmi per renderne efficiente l'esecuzione sui processori paralleli di istruzioni, senza tuttavia interferire con l'analogo parallelismo a livello dei dati. Al livello hardware, le comunicazioni tra le unità funzionali e la sincronizzazione tra processi vengono risolte in una varietà di modi, ad esempio mediante l'uso di variabili comuni, o di reti di interconnessione, o mediante richieste ad un programma supervisore. Al livello software, soltanto negli ultimi anni, in coincidenza con l'introduzione di alcuni sistemi che utilizzano queste architetture, la teoria dei linguaggi di programmazione e la tecnologia dei compilatori hanno cominciato ad affrontare queste problematiche, che sono essenziali per un uso efficiente delle architetture parallele ma che sono tuttavia ancora ben lontane da una soluzione completa, generale e definitiva.
|
|||||||
© 1997-2003 Paolo Marincola (Rome, Italy)
e-mail: pmaNOSPAM@acm.org (eliminare
i caratteri "NOSPAM" per ottenere l'indirizzo esatto)
Commenti, osservazioni e suggerimenti sono estremamente graditi.
Last revised: 2003-12-06 19:42