Reti neurali e riconoscimento di caratteri |
|
La varietà degli algoritmi usati nelle varie fasi funzionali dei sistemi di lettura automatica è senza dubbio enorme, e una loro descrizione completa e accurata va certamente al di là degli scopi del presente rapporto. Ci limiteremo qui dunque a dare una brevissima introduzione ai vari temi, citando in determinati casi alcune tecniche particolarmente rappresentative.
Gli algoritmi di segmentazione devono essere in grado di trattare una grande varietà di tipi documenti, e quindi devono poter individuare ed isolare sia testi costituiti da caratteri anche fortemente variabili come font e dimensioni, sia porzioni grafiche disposte in maniera imprevedibile sulla pagina, sia testi stampati all'interno di porzioni grafiche. Inoltre, le stringhe di caratteri possono, in linea di principio, avere qualunque orientamento nella pagina, non necessariamente orizzontale (come abbiamo visto, ad esempio, nel caso di pagine non perfettamente orientate nello scanner).
E' possibile trovare in letteratura diversi algoritmi per la separazione testo/grafica (Chen et al., 1980; Wahl et al., 1982; Watson et al., 1984; Bley, 1984); molti di essi, tuttavia, impongono condizioni eccessivamente restrittive ai documenti che sono in grado di trattare, e possono pertanto trovare scarsa applicazione in sistemi OCR per usi generali. Ad esempio, l'algoritmo proposto da Chen et al. (1980) incontra una serie di difficoltà quando nella pagina sono presenti caratteri di font e dimensioni diverse, e richiede in questi casi diverse elaborazioni distinte, ciascuna con diversi parametri; per di più, vengono correttamente individuati solo i caratteri orientati lungo una direzione specifica. Inconvenienti analoghi sono da imputare anche all'algoritmo di Bley (1984), mentre la tecnica proposta da Wahl et al. (1982) non è in grado di isolare i caratteri contenuti all'interno dei segmenti grafici.
L'algoritmo descritto da Fletcher e Kasturi (1988) presenta invece diversi aspetti interessanti. Utilizzando un algoritmo dovuto a Fletcher (1986), i pixel dell'immagine vengono raggruppati in componenti connesse (caratteri, simboli, segmenti) circoscritte da rettangoli, e ad ogni rettangolo vengono associate diverse informazioni, quali le coordinate dei suoi vertici, le coordinate di un pixel rappresentativo (seed) del gruppo, il numero di pixel che costituiscono il gruppo, e così via. In generale, un'immagine contiene anche centinaia o migliaia di componenti connesse, le più ampie delle quali possono senz'altro essere classificate come grafiche se il loro fattore di forma è tale da rendere estremamente improbabile l'inclusione di un carattere; le componenti grafiche così individuate vengono allora temporaneamente eliminate dall'immagine per facilitare le successive elaborazioni.
Costruendo un istogramma del numero di componenti per ciascun valore di area dei rettangoli, diviene possibile determinare dei valori di soglia mediante cui isolare ulteriori componenti grafiche dal testo ed eliminarle dall'immagine. Poiché le componenti associate ai caratteri di una stringa sono allineate lungo una stessa direzione, è sufficiente a questo punto determinare le direzioni di massimo allineamento delle componenti connesse rimaste sull'immagine. Una volta individuati i segmenti di retta corrispondenti a tali allineamenti, è ancora possibile ordinare le componenti relative in base alla loro posizione lungo la retta, e determinare quindi i raggruppamenti di caratteri in parole e in frasi.
Le componenti connesse collineari vengono individuate applicando la trasformata di Hough ai centri di massa dei rettangoli che circoscrivono le componenti connesse stesse. La trasformata di Hough converte segmenti di retta in punti (Duda & Hart, 1972; Pratt, 1978): una retta nello spazio cartesiano (x, y) data dall'equazione
r = x cos q + y sin q
viene trasformata in un punto (r, q) nel dominio di Hough; analogamente, ogni punto (x, y) nello spazio cartesiano viene trasformato in una curva. Tutte le curve corrispondenti a punti collineari si incontrano in uno stesso punto (r, q) nello spazio di Hough, con r e q che specificano i parametri della retta che unisce i punti in questione.
Una volta individuate le stringhe di caratteri mediante la trasformata di Hough, tutte le componenti connesse ad esse corrispondenti vengono cancellate dall'immagine; le componenti restanti vengono infine trattate come aree grafiche, oppure l'immagine residua viene trattata nel suo complesso come un'unica area grafica. L'algoritmo dà ottimi risultati, ma è piuttosto complesso e richiede una quantità notevole di operazioni, e va dunque posta particolare cura nella sua implementazione se si vogliono ottenere tempi di esecuzione accettabili.
Nell'analisi delle immagini un problema ricorrente è quello di stabilire se all'interno di una data immagine è presente o meno un pattern prestabilito (template); la soluzione a questo problema può essere anche utilizzata in applicazioni di riconoscimento di pattern, quando il test di presenza venga eseguito per tutti i possibili pattern campione.
La tecnica classica impiegata per affrontare questa categoria di problemi è detta template matching. Nella maggior parte delle applicazioni pratiche, non è realistico aspettarsi di trovare una copia esatta del pattern campione u(m, n), e diventa dunque importante una misura quantitativa della somiglianza tra il template e una regione dell'immagine v(m, n) di ugual superficie, traslando il template in tutte le possibili posizioni (p, q). E' possibile in tal caso definire una misura di dissomiglianza s2(p, q) come fosse un'energia:
| s2(p, q) | = | Sm Sn [v(m, n) - u(m - p, n - q)]2 = |
| = | Sm Sn |v(m, n)|2 + Sm Sn |u(m, n)|2 + | |
| -2 Sm Sn v(m, n) u(m - p, n - q) |
Affinché s2(p, q) raggiunga un valore minimo, è sufficiente massimizzare il terzo termine dell'espressione, cioè la cross-correlazione:
cvu = Sm Sn v(m, n) u(m - p, n - q)
Per la disuguaglianza di Cauchy-Schwarz, abbiamo però:
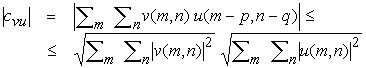
dove l'uguaglianza è verificata se e solo se
v(m, n) = a u(m - p, n - q)
con a costante arbitraria che può essere posta ad 1. In altri termini, la cross-correlazione cvu raggiunge un massimo quando la posizione traslata del template coincide con la regione di immagine osservata. Otteniamo dunque:
cvu(p, q) = Sm Sn |v(m, n)|2 > 0
e il massimo richiesto ha luogo quando in una particolare posizione dell'immagine esiste una copia perfetta del template; è dunque possibile localizzare un pattern u(m, n) all'interno di un'immagine cercando i picchi della funzione di cross-correlazione.
Può spesso accadere che il template non debba essere soltanto traslato sull'immagine per trovare una concordanza, ma debba anche essere ruotato o cambiato di scala; ad esempio:
v(m, n) = a u((m - p') / z, (n - q') / h; q)
dove z e h sono i fattori di scala, (p', q' ) sono le coordinate della traslazione e q è l'angolo di rotazione della regione di immagine rispetto al template. In casi del genere i massimi della funzione di cross-correlazione vanno cercati nello spazio dei parametri (p', q', z, h, q); simili ricerche generalizzate possono tuttavia diventare impraticabili sotto l'aspetto computazionale, a meno che non sia possibile determinare in anticipo una stima ragionevole di z, h e q.
La funzione di cross-correlazione cvu(p,q), detta anche correlazione di area, può essere calcolata, oltre che direttamente, anche come trasformata inversa di Fourier della funzione
Cvu(w1, w2) = V(w1, w2) U*(w1, w2)
dove U e V sono le trasformate di Fourier di u e, rispettivamente, di v, e U* è il complesso coniugato di U. Il calcolo diretto della correlazione d'area è conveniente quando la superficie del pattern è piccola rispetto a quella dell'immagine in cui esso va cercato; in caso contrario, è preferibile ricorrere a una trasformata rapida di Fourier (Fast Fourier Transform, FFT) di dimensioni opportune.
La tecnica del template matching è particolarmente efficiente quando i dati sono binari, come avviene appunto nel riconoscimento di caratteri; in questo caso, è sufficiente cercare i minimi della differenza binaria totale:
gvu(p, q) = SS [v(m, n) Å u(m – p, n – q)]
dove Å rappresenta l'operazione booleana di OR esclusivo. La quantità gvu(p, q) dà allora il numero di pixel dell'immagine che non coincidono con quelli del template posizionato alle coordinate (p, q).
L'analisi e la classificazione di un pattern possono essere grandemente facilitate se il pattern, anziché essere presentato al classificatore nella sua struttura originale, viene descritto in maniera adeguata. Lo scopo principale delle tecniche di pre-elaborazione non è dunque quello di mantenere quanta più informazione possibile nella descrizione del pattern, quanto quello di individuare il minor numero possibile di informazioni necessarie per una corretta classificazione. Una interessante panoramica delle varie tecniche di questo tipo è stata preparata da Pavlidis (1978), che ha anche proposto una loro suddivisione in rappresentazioni nel dominio spaziale, adatte alla classificazione di tipo strutturale, e rappresentazioni con trasformazione scalare, più adatte alla classificazione di tipo numerico; appartengono a quest'ultima classe, ad esempio, le rappresentazioni che usano maschere (Nagy, 1969; Andrews et al., 1968), i fattori di forma (Danielsson, 1978), i momenti geometrici (Hu, 1962; Dudani et al., 1977; Wong & Hall, 1978), le trasformate di Fourier (Granlund, 1972; Persoon & Fu, 1987) ed altre espansioni in serie. Pavlidis (1978) stabilisce poi un'ulteriore distinzione tra trasformazioni interne e esterne, a seconda che di un pattern vengano utilizzati tutti i punti significativi oppure, rispettivamente, soltanto quelli appartenenti al suo contorno.
I momenti geometrici sono stati spesso utilizzati per normalizzare i pattern (Nagy & Tuong, 1970) e per estrarre le feature da applicare al classificatore (Cash & Hatamian, 1987). Dato un generico pattern bidimensionale sotto forma di una funzione f(x, y) di due variabili il momento di ordine (m+n) è definito come
mmn = Sx Sy xmyn f(x, y)
ed è possibile dimostrare come esista sempre una relazione biunivoca tra l'insieme completo dei momenti {mmn | m,n = 1, 2, ...} e f(x, y). Ponendo poi:
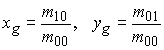
che sono le coordinate del centro di massa del pattern, possono essere definiti i momenti centrali, invarianti per traslazione:
mmn = Sx Sy (x – xg)m (y – yg)n f(x, y)
Ulteriori trasformazioni possono poi condurre a definire dei momenti invarianti per rotazione e per cambiamento di scala; inoltre, diversi altri importanti parametri legati al pattern possono essere derivati senza difficoltà da un insieme finito di momenti.
I coefficienti della trasformata discreta di Fourier forniscono un ulteriore esempio di relazione biunivoca tra un pattern e un set di parametri. Sebbene di solito si usi direttamente la funzione f(x, y) per calcolarne la trasformata discreta di Fourier, della quale utilizzare un sottoinsieme dei coefficienti come feature, è anche possibile in taluni casi determinare i descrittori di Fourier del contorno del pattern. Sia dato un insieme di punti (xi, yi), con i = 0, 1, ... , N e con (x0, y0) = (xN, yN), che costituisca il campionamento in verso orario di una curva chiusa semplice di lunghezza L. Il primo metodo di parametrizzazione è basato sulla lunghezza d'arco li tra (x0, y0) e (xi, yi) e l'angolo b(li) tra la tangente alla curva in (x0, y0) e la tangente in (xi, yi). L'angolo b viene poi normalizzato in:
a(t) = b Lt / 2p, 0 £ t < 2p
che è invariante per traslazione, rotazione e cambio di scala, e trasforma curve semplici chiuse in funzioni periodiche su (0, 2p). I descrittori (complessi) di Fourier sono in tal caso:
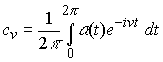
Il secondo metodo è invece basato su una rappresentazione parametrica definita come funzione complessa j(l) = x(l) + iy(l) del contorno descritto da x(l), y(l). In questo caso i descrittori di Fourier sono calcolati come:
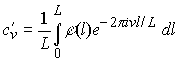
Il calcolo di cvu e c'vu nel caso discreto, qual è quello del pattern di un carattere ripreso attraverso uno scanner, viene descritto, ad esempio, in Persoon & Fu, 1977. Una importante differenza tra i due tipi di descrittori è che un sottoinsieme di {cvu} di solito non consente di riottenere una curva chiusa prossima a quella originaria, cosa invece possibile con un sottoinsieme di {c'vu}.
Anche le tecniche nel dominio spaziale possono essere suddivise in interne ed esterne. Tra le prime vi sono le proiezioni (Nakimoto et al., 1973; Wong & Steppe, 1969; Tasto, 1977), la trasformazione in asse mediano (Rosenfeld & Pfaltz, 1966; Blum & Nagel, 1978), e una gran varietà di altri metodi di decomposizione del pattern. Le proiezioni possono essere definite in vari modi, come ad esempio le proiezioni di una funzione f (x, y) sugli assi x, y date da:
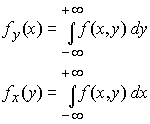
con l'avvertenza che fx(y) e fy(x) possono anche risultare identiche per pattern differenti, e che è possibile ottenere una ulteriore generalizzazione ricorrendo a proiezioni lungo direzioni arbitrarie.
Se si immagina un fronte di onde sferiche che si propaga da ciascun punto del contorno di un pattern verso il suo interno, il luogo di tutti quei punti sui quali i fronti d'onda si incontrano durante la propagazione si chiama asse mediano del pattern (Blum, 1964). Gli algoritmi per la trasformazione in asse mediano hanno lo scopo di mantenere inalterata la forma del pattern eliminando però le informazioni relative allo spessore dei tratti che lo compongono, e si suddividono in due grandi classi: le tecniche di scheletrizzazione, in cui ciascun punto dello scheletro è definito in termini di distanza dai punti più vicini del contorno, e quelle di thinning, che trasformano un pattern in una serie di archi digitali semplici giacenti approssimativamente lungo gli assi mediani (Rutovitz, 1966; Davies & Plummer, 1981).
Contrariamente alla parametrizzazione in feature, invece, la decomposizione di un pattern tende a trovare e raggruppare componenti concettualmente semplici che, una volta ricombinate in maniera opportuna, siano in grado di ricostruire con buona approssimazione il pattern originale. Ad esempio, se è possibile approssimare il bordo di un pattern con segmenti rettilinei, è ragionevole pensare di prendere in considerazione solo lati di poligoni regolari; il pattern originale può allora essere decomposto usando come componenti opportuni sottoinsiemi convessi dei poligoni campione. Tali metodi sono peraltro molto più adatti alla descrizione del pattern che non alla sua classificazione, e quindi trovano pochissime applicazioni nel campo del riconoscimento dei caratteri.
Abbiamo più volte sottolineato nei capitoli precedenti come nei sistemi OCR siano essenzialmente due le categorie di classificatori usati per il riconoscimento dei caratteri: la prima, che comprende le tecniche di classificazione basate sul template matching, è quella più largamente utilizzata nei lettori commerciali di basso costo, mentre la seconda, basata sull'analisi delle feature, è quella più vivamente raccomandata nei lavori di ricerca (Shillman, 1974; Ullmann, 1976; Srihari, 1984; Kahan, 1985) e che trova sempre maggior impiego nei lettori commerciali di classe elevata. In questa sezione, cercheremo di dare ulteriori dettagli su queste due metodologie.
In termini generali, la scelta delle feature da utilizzare per la descrizione di un pattern è molto più legata al problema specifico che non il processo di classificazione: un buon set di feature per il riconoscimento di caratteri, ad esempio, sarebbe quasi certamente di ben scarsa utilità nell'identificazione di impronte digitali o nella classificazione di microfotografie di cellule sanguigne. Di per sé, il processo di classificazione consiste essenzialmente nel partizionamento dello spazio dei parametri in tante regioni quante sono le categorie alle quali assegnare i pattern di ingresso. In condizioni ideali, tale partizionamento non dovrebbe mai produrre decisioni errate; nella realtà, tuttavia, l'unico obiettivo ragionevole da perseguire è quello di ridurre al minimo la probabilità di errore o, in generale, quando gli errori producono effetti non del tutto equivalenti, minimizzare il costo medio di una decisione errata. Posto in questi termini, il problema della classificazione può essere ricondotto nell'ambito della teoria statistica delle decisioni (Wald, 1950; Blackwell & Girshick, 1954; Chernoff & Moses, 1959; Ferguson, 1967).
Sia W = { w1, ..., wn } l'insieme finito delle categorie ideali -- che chiameremo stati di natura (Duda & Hart, 1973) -- a cui appartengono i pattern da classificare, A = { a1, ..., aa } l'insieme finito delle possibili decisioni, ossia delle categorie a cui possiamo pensare di assegnare un pattern, e l(ai | wj) la penalità dovuta alla decisione ai quando lo stato di natura è wj (Wald, 1939). Se il pattern è descritto da un vettore x, considerato come variabile aleatoria vettoriale a d componenti, allora indichiamo con p(x | wj) la densità di probabilità condizionata per x, cioè la densità di probabilità della realizzazione x quando lo stato di natura sia wj. Se P(wj) è la probabilità a priori associata allo stato di natura wj, allora la probabilità a posteriori P(wj | x) può essere calcolata da p(x | wj) mediante la regola di Bayes:
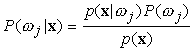
dove
p(x) = Sj p(x | wj) P(wj)
Supponiamo di osservare un particolare x e di decidere per l'assegnazione alla categoria ai; se lo stato di natura è wj, incorreremo in una penalità l(ai | wj). Poiché P(wj | x) è la probabilità che la vera categoria del pattern sia wj, l'assegnazione alla categoria ai produrrà una penalità attesa che è semplicemente
R(ai | x) = Sj l(ai | wj) P(wj | x)
Nella terminologia della teoria della decisione, la penalità attesa è detta rischio, e R(ai | x) è noto come rischio condizionato. Per ogni particolare osservazione x possiamo minimizzare la penalità attesa scegliendo quella categoria che minimizza il rischio condizionato; un comportamento di questo genere coincide in pratica con la procedura bayesiana di decisione ottimale. Il rischio minimo risultante è chiamato rischio di Bayes, e rappresenta la migliore prestazione che possiamo sperare di conseguire.
Nei problemi di classificazione gli stati di natura vengono posti in corrispondenza biunivoca con le categorie (anche se in molti casi può tornar comoda una categoria in più corrispondente a una decisione di rifiuto, nel caso di pattern inclassificabili), per cui si ha s = a; la scelta ai viene allora di norma interpretata come la decisione che il vero stato di natura è wj. Se prendiamo la decisione ai e il vero stato di natura è wj, la decisione è ovviamente corretta se i = j ed è in errore se i ¹ j. Al fine di evitare il più possibile gli errori, è naturale cercare una regola di decisione che minimizzi la probabilità media di errore, cioè il tasso di errore.
Una funzione di penalità di particolare interesse in questo caso è la cosiddetta funzione di penalità simmetrica (detta anche zero-uno):
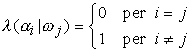
Con questa funzione viene assegnata una penalità unitaria ad ogni errore, rendendo dunque tutti gli errori ugualmente costosi, mentre non viene data alcuna penalità nel caso di decisione corretta. Il rischio corrispondente alla funzione di penalità simmetrica coincide con la probabilità media di errore, poiché il rischio condizionato è:
| R(ai | x) | = | Sj l(ai | wj) P(wj | x) |
| = | Sj¹i P(wj | x) | |
| = | 1 - P(wi | x) |
e P(wi | x) è la probabilità condizionata che l'assegnazione ai sia corretta. La regola di decisione di Bayes per il rischio minimo richiede la scelta della decisione che minimizza il rischio condizionato; per minimizzare la probabilità media di errore, dovremo quindi scegliere quel valore di i che massimizza la probabilità a posteriori P(wi | x). In altre parole, per conseguire il minimo tasso di errore occorrerà decidere per la categoria wi se
P(wi | x) ³ P(wi | x) "j ¹ i
Un classificatore può essere utilmente descritto come un insieme di funzioni discriminanti gi(x), per i = 1, 2, ... , s, dove s è il numero delle categorie (Fisher, 1936; Nilsson, 1965). Diremo che il classificatore assegna un vettore di feature x alla classe wi se
gi(x) > gj(x) "j ¹ i
Il classificatore viene così descritto come una macchina che calcola s funzioni discriminanti e sceglie la categoria corrispondente al discriminante di massimo valore. Con queste premesse, diventa possibile rappresentare il classificatore di Bayes in maniera semplice e naturale; nel caso generale, possiamo porre:
gi(x) = - R(ai | x)
in modo che la funzione discriminante col massimo valore corrisponderà al minimo rischio condizionato. Nel caso del minimo tasso di errore, possiamo procedere ad un'ulteriore semplificazione ponendo:
gi(x) = P(wi | x)
sicché la funzione discriminante col massimo valore corrisponderà alla massima probabilità a posteriori.
E' chiaro che la scelta delle funzioni discriminanti non è univoca: ad esempio, è sempre possibile moltiplicare le funzioni discriminanti per una costante positiva, oppure sommare ad esse una costante, senza influenzare l'esito della decisione. Più in generale, se sostituiamo ogni gi(x) con f (gi(x)), dove f è una funzione monotonicamente crescente, la classificazione risultante rimane immutata. Questa osservazione può spesso condurre a significative semplificazioni, sia sotto l'aspetto analitico che sotto quello computazionale; in particolare, nel caso della classificazione a minimo tasso di errore, ciascuna delle seguenti alternative fornisce identici risultati di classificazione:
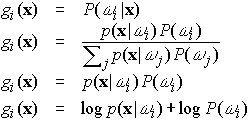
Tuttavia, alcune di esse possono risultare di significato più immediato ovvero più semplici da calcolare rispetto alle altre.
Sebbene le funzioni discriminanti possano assumere molte forme diverse, le regole di decisione sono in ogni caso equivalenti, e consentono di suddividere lo spazio delle feature in regioni di decisione R1, ... , Rs. Se gi(x) >> gj(x) per ogni j ¹ i, allora x è in Ri, e la regola di decisione comporta l'assegnazione di x ad wi. Le regioni di decisione sono separate da confini di decisione, cioè da superfici nello spazio delle feature le cui intersezioni reciproche sono i luoghi di uguale probabilità. Se Ri e Rj sono contigue, l'equazione per il confine di decisione che le separa è:
gi(x) = gj(x)
Benché questa equazione possa apparire sotto diverse forme a seconda della forma scelta per le funzioni discriminanti, i confini di decisione sono tuttavia gli stessi. La classificazione di un vettore di feature giacente sul confine di decisione non è univocamente definita: per un classificatore bayesiano, ad esempio, il rischio condizionato associato a ciascuna decisione è lo stesso, e non ha dunque importanza quale delle due decisioni venga presa.
Il concetto che sta alla base di quasi tutte le tecniche di post-elaborazione usate nei sistemi OCR come alternativa o come ausilio alla correzione manuale degli errori, prevede la raccolta e l'uso della maggior quantità possibile di informazioni contestuali presenti nel testo ricavato dal processo di lettura sia per la correzione degli errori di classificazione dei singoli caratteri, difficilmente evitabili, sia per le decisioni relative ai caratteri che il classificatore non riesce ad assegnare ad alcuna categoria. Moltissime tecniche di post-elaborazione richiedono il supporto di un dizionario delle parole considerate valide (tecniche di correzione ortografica o spelling check), mentre quando i tempi necessari per le ricerche nel dizionario vengono considerati inaccettabili è possibile ricorrere a considerazioni statistiche legate alla probabilità di apparizione di determinate sequenze di caratteri in una data lingua. In linea di principio, le due metodologie possono anche coesistere nello stesso sistema; in ogni caso, l'obiettivo finale è quello di ridurre ulteriormente il tasso di errore intrinseco del classificatore senza richiedere interventi manuali da parte dell'operatore del sistema di lettura.
Un interessante esempio di post-elaborazione con spelling check è riportato da Kahan et al. (1987). Le parole generate all'uscita dei vari stadi del classificatore vengono in primo luogo sottoposte al programma UNIX spell (McIlroy, 1982), al fine di identificare le parole ortograficamente scorrette; quando una di queste viene individuata, viene generata una lista di possibili parole alternative e dei relativi costi (che verranno definiti tra breve). Le varianti vengono esaminate in ordine di costo crescente, e quelle che risultano ancora ortograficamente scorrette vengono a loro volta sostituite da una corrispondente lista di varianti. Il processo prosegue fin quando non viene trovata una parola corretta, oppure fin quando il costo della variante più economica diventa eccessivo.
Nella fase di addestramento del classificatore, per ciascuna coppia ordinata di classi di caratteri {z, h} viene calcolata una stima della probabilità di confusione Pzh, definita come la probabilità che un carattere della classe h venga classificato come appartenente alla classe z (è chiaro che un buon classificatore dovrebbe sempre garantire che Pzz ³ Pzh per ogni coppia z, h); per ogni classe z viene poi generato un elenco di classi di confusione h tali che Pzh> 0, che verrà usato per generare le varianti con la tecnica che vedremo tra breve.
Se W0 = c01 c02 ... c0n è la parola emessa dal classificatore, il costo di una sua variante ortografica W = c1 c2 ... cn è definito come
![]()
Se W0 è dichiarata ortograficamente scorretta, una sua variante viene generata sostituendone un dato carattere con il più probabile della sua classe di confusione; da W0 si ottengono così n varianti:
c01 c02
... c0n
c01 c12 ... c0n
...
c01 c02 ... c1n
Una volta calcolato il costo delle varianti generate, esse vengono ordinate in una lista secondo costi crescenti. Ad ogni iterazione dell'algoritmo, viene presa in considerazione la variante di costo minimo: se lo spelling checker la considera ortograficamente corretta, essa viene usata per sostituire la parola originale; altrimenti viene a sua volta sostituita nella lista da un elenco delle sue varianti, e la lista viene nuovamente riordinata. Dal momento che, se il classificatore è di qualità sufficientemente elevata, un programma come spell rifiuta un numero relativamente basso di parole, e che raramente le parole rifiutate hanno più di un carattere errato, il tempo di post-elaborazione e correzione viene ad essere solo una piccola frazione del tempo totale di riconoscimento del documento.
|
|||||||
© 1997-2003 Paolo Marincola (Rome, Italy)
e-mail: pmaNOSPAM@acm.org (eliminare
i caratteri "NOSPAM" per ottenere l'indirizzo esatto)
Commenti, osservazioni e suggerimenti sono estremamente graditi.
Last revised: 2003-11-09 00:29