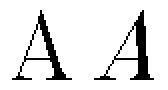Reti neurali e riconoscimento di caratteri |
|
In questo capitolo viene presentata una descrizione di massima dell'architettura funzionale di un sistema OCR di classe mid-range che, in base alle considerazioni finora svolte, riteniamo tecnologicamente fattibile e commercialmente significativo. Una volta presentate le specifiche generali del sistema, vengono discussi nel dettaglio sia il flusso dei dati attraverso le varie componenti dell'apparato, sia i vari processi di elaborazione a cui tali dati vengono sottoposti; in presenza di problemi particolari per i quali l'ottimalità di una data soluzione non sia stata dimostrata nei rapporti di ricerca reperibili in letteratura né sia ancora emersa dagli esperimenti specifici che abbiamo condotto o stiamo conducendo (descritti alla Sez. 11), vengono presentate e discusse le diverse alternative che riteniamo percorribili.
L'ambiente a cui il sistema di lettura proposto si rivolge principalmente è quello di ufficio, che ha di norma molti documenti da trattare, e può impiegare al compito di data entry solo personale non specializzato che non ha peraltro quasi mai la possibilità di rimanere dedicato a tale compito. I documenti da leggere sono dei tipi più diversi (lettere, riviste, moduli, libri, manuali, etc.), spesso pieni di informazioni grafiche difficili da riprodurre manualmente ma assolutamente da riutilizzare. I caratteri nei testi hanno dimensioni molto variabili, dai titoli cubitali nei giornali alle note a piè pagina nei libri, e possono appartenere a font anche molto diversi. In molte circostanze, poi, specialmente in ambienti che trattano grandi quantità di modulistica, è sommamente importante poter leggere solo determinate regioni del documento, ignorando completamente le informazioni contenute al di fuori di esse.
Il dispositivo di input del documento è normalmente uno scanner flat-bed operante in modalità manuale o auto-feed, ma può anche essere un economico scanner manuale quando si debbano estrarre articoli da colonne di giornale; in alternativa, l'input può anche provenire da un file grafico trasmesso ad esempio attraverso una rete locale, o addirittura da un'interfaccia fax che generi un opportuno file grafico.
Il costo del sistema deve essere contenuto, in modo che il relativo investimento non crei grossi problemi di budget e possa essere ammortizzato in tempi brevi. Inoltre, è da tener presente che ambienti esperti sotto l'aspetto informatico gradiscono poco sistemi implementati su calcolatori rigidamente predeterminati, e preferiscono di gran lunga la possibilità di espandere e riconfigurare in maniera opportuna le macchine già disponibili. Dal momento che una grandissima percentuale dei calcolatori installati negli ambienti di ufficio è oggi del tipo PC IBM, riteniamo indispensabile che un sistema di lettura sia compatibile con tali macchine.
L'input del documento deve poter provenire:
Deve inoltre essere prevista la compatibilità con il maggior numero possibile di modelli di scanner commerciali; la relativa interfaccia deve dunque essere riconfigurabile e adattabile.
La corretta lettura del documento non deve essere pregiudicata da un imperfetto inserimento del foglio entro lo scanner, deve cioè essere ampiamente tollerante verso orientamenti anomali del foglio (in particolare, verso rotazioni di 90 o 180 gradi). Le regioni grafiche, contenenti cioè informazioni diverse dai testi, devono poter essere identificate automaticamente, estratte e archiviate separatamente in file di formato standardizzato per consentirne il successivo riutilizzo. Deve anche essere possibile imporre la lettura di testo e/o grafica solo entro regioni predefinite della pagina. Deve infine essere possibile identificare automaticamente le varie colonne su cui possa essere organizzato il testo, come pure deve essere possibile accodare i testi estratti da colonne contigue.
Il riconoscimento dei caratteri deve avvenire in misura largamente indipendente dal font e dalla dimensione; devono poter essere riconosciuti correttamente sia caratteri molto piccoli (corpo 6) sia caratteri molto grandi come quelli presenti su titoli di articoli nei quotidiani. Deve esser possibile ricavare informazioni anche sulle caratteristiche di formattazione del testo (marginatura, giustificazione, etc.) e sulle varianti stilistiche dei caratteri (grassetto, corsivo, etc.), e memorizzare tali informazioni o su appositi stylesheet o all'interno dei file di testo, in formato riconoscibile dai più diffusi word processor commerciali.
Deve essere possibile una fase di editing finale, con ricerca rapida e automatizzata degli eventuali errori commessi in fase di riconoscimento, e con suggerimento di possibili alternative all'utente; l'utente deve tuttavia poter escludere a piacimento una tale fase, ovvero deve poterla posticipare ad altro momento.
I file di testo in uscita dal sistema devono avere formato ASCII puro, oppure formato compatibile con i più diffusi word processor commerciali (Word, WordPerfect, WordStar, etc.). I file grafici in uscita dal sistema devono avere formato compatibile con i più diffusi pacchetti commerciali di editing grafico (DrHalo, PaintBrush, etc.) e di desktop publishing (Ventura Publisher, PageMaker, etc.).
L'interfaccia tra l'utente e il sistema deve essere molto flessibile, nel senso che deve poter essere riconfigurata sia per operare in modalità command line per utenti esperti che desiderino attivare rapidamente le funzioni del sistema, sia per presentare un ambiente user-friendly per utenti poco esperti, con menù a finestre, icone autoesplicative, help in linea, uso del mouse e navigazione guidata attraverso le funzioni del sistema.
Ad ogni istante l'utente deve essere in grado di conoscere con esattezza lo stato del sistema e il grado di avanzamento del processo di lettura, come pure deve essere avvertito tempestivamente degli inconvenienti o dei problemi che si dovessero presentare nel corso delle elaborazioni. Tutta la sequenza delle operazioni deve essere costantemente registrata in un log file consultabile a piacimento dall'utente.
A supporto del processo di lettura, deve essere resa disponibile una serie di utility per la conversione dei formati dei file (sia di ingresso che di uscita), per la copia o il cambiamento di nome dei file, per l'editing grafico del documento di input o dei file grafici di output; è opportuno che tutte queste operazioni possano essere eseguite senza che sia necessario abbandonare il programma di supervisione del sistema.
Il software di supervisione deve essere disponibile sia in modalità stand-alone, con interazione diretta da parte dell'utente, sia sotto forma di libreria integrabile in applicazioni di più alto livello. Nel primo caso, il grado di interazione tra utente e sistema deve essere variabile da un massimo, in cui l'utente mantiene sotto controllo dettagliato tutte le fasi del processo di lettura, a un minimo, in cui l'utente attiva un processo multiplo di lettura per una serie di documenti e interviene solo a processo concluso. Nel secondo caso, la libreria deve essere compatibile con i più diffusi compilatori per linguaggio C; peraltro, essendo questo il più diffuso linguaggio di sviluppo, non si ritiene necessaria la compatibilità con altri linguaggi.
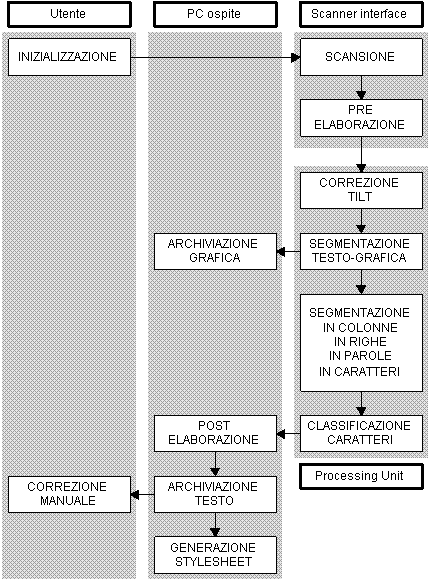
Al fine di soddisfare i requisiti contemporanei di flessibilità, velocità e costi contenuti, la soluzione migliore sembra quella di usare un calcolatore PC-compatibile come piattaforma di supporto e due schede specializzate (Scanner Interface e Processing Unit, le cui funzioni e la cui struttura verranno delineate più avanti) come periferiche intelligenti. La struttura a blocchi del sistema risultante è raffigurata nel diagramma di Fig. 26, e qui di seguito vengono illustrati in dettaglio i compiti assegnati a ciascun blocco.
|
||
|
La fase di inizializzazione è dedicata all'impostazione dei parametri operativi del sistema e alla definizione delle varie opzioni disponibili all'utente. E' in questa fase che vengono definite le maschere di lettura, cioè le regioni del documento entro le quali deve avvenire il processo di riconoscimento, oppure le selezioni relative al formato dei file di uscita.
L'utente può intervenire manualmente per lo svolgimento di questa fase, oppure può utilizzare un file di configurazione per la definizione delle varie opzioni; questa seconda alternativa è molto utile ad esempio quando il tipo di documenti da elaborare varia in continuazione, ma si ripete più o meno periodicamente: in tal caso l'utente può creare una libreria di file di configurazione da richiamare di volta in volta.
Il processo di lettura viene attivato dal modulo software supervisore mediante l'invio allo scanner di un comando di inizio scansione. Quando il sistema opera in modalità auto-feed, la scansione del documento deve ovviamente essere preceduta dall'inserimento automatico di un nuovo foglio nello scanner; quando invece la modalità operativa è manuale, il modulo supervisore avverte l'operatore della necessità di inserire un documento nello scanner, e rimane in attesa del completamento dell'operazione.
Nel corso della scansione del documento, le informazioni binarie che ne risultano vengono organizzate e pre-elaborate in tempo reale, secondo le modalità più avanti descritte, all'interno della Scanner Interface, e trasferite sotto forma di matrice binaria nella memoria della Processing Unit. Sia il calcolatore ospite sia la Processing Unit hanno la possibilità di interrogare la Scanner Interface per avere informazioni sul numero di linee di scansione completamente acquisite ad un dato istante; in tal modo, la Processing Unit può cominciare le proprie elaborazioni ancor prima che l'intera immagine sia stata portata in memoria, mentre il calcolatore ospite può utilizzare tale informazione a fini di monitoraggio del processo.
Al completamento della scansione, se il sistema opera in modalità auto-feed viene attivato l'inserimento di un nuovo foglio dal feeder, in maniera da sovrapporre i tempi meccanici necessari per questa funzione con i tempi di elaborazione del documento precedente; se invece il sistema opera in modalità manuale, lo scanner si arresta in attesa che l'operatore ritiri il documento ormai acquisito e inserisca il successivo.
Se il processo di lettura deve essere applicato solo su alcune porzioni della pagina, sono previste due alternative: se la regione è una sola ed ha forma rettangolare, è possibile istruire certi modelli di scanner ad acquisire soltanto le informazioni relative a quell'area; in caso contrario, lo scanner acquisisce l'intera pagina e le aree vengono delimitate manualmente dall'operatore in fase di setup, oppure le coordinate relative vengono estratte da un apposito file. Naturalmente, nel caso di aree multiple il processo di lettura viene partizionato in altrettanti processi indipendenti, e sarà poi cura dell'operatore determinare eventuali relazioni tra i corrispondenti file di uscita.
Se il documento da sottoporre a lettura risiede sul calcolatore ospite sotto forma di file grafico, esso viene convertito nel formato richiesto dalla Processing Unit e trasferito alla Scanner Interface se sono richieste le operazioni di pre-elaborazione, altrimenti viene trasferito direttamente alla Processing Unit per i successivi trattamenti.
La presenza di rumore sull'immagine, se in quantità non eccessiva, solo in rari casi può pregiudicare la corretta interpretazione del testo; in molte circostanze, tuttavia, essa può indurre un aumento dei tempi necessari per la segmentazione della pagina o per la classificazione dei caratteri, poiché il numero di pixel da elaborare può aumentare in maniera significativa. E' dunque sempre raccomandabile un'operazione di filtraggio per la riduzione del rumore di acquisizione, il cui effetto principale è di norma l'apparizione di un gran numero di pixel neri isolati.
La ricerca nel campo dell'elaborazione di immagini ha portato allo studio di una quantità innumerevole di filtri digitali per la riduzione del rumore, ma la gran parte di questi è di tipo lineare e, quando applicata ad un'immagine binaria, produce in uscita un'immagine multilivello, che per essere poi nuovamente ricondotta a valori binari deve essere sottoposta ad un'ulteriore operazione di sogliatura. Vi è però una classe di filtri non-lineari, detti median filter (Tukey, 1971; Huang et al., 1979; Ataman et al., 1980; Gallagher & Wise, 1981; Fitch et al., 1985; Astola & Campbell, 1989), dall'implementazione piuttosto complessa nel caso generale ma estremamente semplice nel caso di immagini binarie, molto efficaci per l'eliminazione dei pixel isolati. Dato un generico pixel p(x, y) dell'immagine da filtrare, l'ingresso al filtro è costituito dai valori di tutti i pixel che giacciono in una finestra bidimensionale di lato dispari 2s+1 centrata su di esso; l'operazione del median filter consiste nell'ordinare i pixel
p(x + i, y + j), con i, j = 0, ±1, ..., ±s
per valore decrescente in una successione
q1, q2, ..., qk k = (2s + 1)2
e nell'emettere in uscita il valore qk/2+1, che va a sostituire il valore originale del pixel p(x, y). L'immagine viene filtrata applicando l'operazione descritta a tutti i suoi pixel, e non è difficile dimostrare come tutti i pixel neri isolati possano venire eliminati utilizzando una finestra di lato 3; per di più, il filtro consente in molti casi di regolarizzare il profilo di un pattern che sia rimasto soggetto ad erosione. E' facile convincersi che, nel caso di immagini bilivello, l'uscita del median filter coincide col valore dei pixel più frequenti nella finestra, per cui è sufficiente un semplice conteggio dei soli pixel neri per determinare il valore dell'uscita, rendendone così abbastanza semplice un'implementazione in tempo reale.
Al termine delle operazioni di pre-elaborazione e filtraggio, che vengono eseguite all'interno della Scanner Interface, l'immagine risultante viene trasferita nella memoria della Processing Unit per le successive elaborazioni.
La prima operazione che viene eseguita sull'immagine all'interno della Processing Unit è la correzione dell'orientamento della pagina, o compensazione del tilt, rispetto agli assi dello scanner; come accennato al la Sez. 6, infatti, la rotazione della pagina di un angolo anche piccolo può pregiudicare la corretta lettura del documento. Questo processo, che è opzionale e può essere configurato dall'operatore del sistema nella fase di setup, ha lo scopo di allineare le linee di testo in direzione preferenzialmente orizzontale, quella cioè più adatta per semplificare un certo numero di operazioni successive, quale ad esempio l'identificazione delle linee di testo mediante analisi delle proiezioni sull'asse verticale.
L'algoritmo che proponiamo come base per la correzione del tilt è basato sulla trasformata di Hough di una versione dell'immagine a risoluzione ridotta, e daremo di esso una sommaria descrizione al la Sez. 11, dove diremo anche di alcuni esperimenti preliminari per verificarne l'efficacia.
Una volta rilevata l'entità della rotazione dell'immagine, la correzione del tilt equivale a generare una nuova immagine mediante la rotazione della prima di un angolo uguale ed opposto a quello del tilt misurato. Questo processo, sebbene piuttosto costoso sotto l'aspetto della complessità computazionale, è a nostro avviso in molti casi indispensabile per non limitare le prestazioni degli algoritmi che seguono.
La rotazione dell'immagine introduce un certo grado di distorsione sui pattern dei caratteri; esperimenti appositamente condotti hanno tuttavia stabilito che tale distorsione può senz'altro essere considerata trascurabile quando la risoluzione della scansione sia sufficientemente elevata (300-400 dpi). In realtà la distorsione da rotazione può essere considerata come una particolare forma di rumore introdotto sul contorno dei pattern, e come tale deve quindi risultare irrilevante ai fini delle prestazioni di un classificatore per lettura omnifont, che per definizione non deve essere sensibile a piccole imperfezioni dei pattern.
L'operazione successiva ha lo scopo di segmentare la pagina in regioni contenenti testo e in regioni contenenti informazioni grafiche, che possano essere quindi trattate separatamente e nella maniera più opportuna. In particolare, le regioni classificate come contenenti testo verranno sottoposte ad ulteriori processi di segmentazione in parole e caratteri, mentre le regioni contenenti grafica verranno archiviate e successivamente ignorate.
Ai fini del processo di lettura e della successiva ricostruzione, la pagina viene rappresentata come una struttura di dati ad albero, la cui radice è la pagina completa e i nodi di primo livello sono le varie regioni. Le aree grafiche sono prive di nodi discendenti, mentre le aree di testo hanno nodi di secondo livello che rappresentano le righe; ogni nodo di riga possiede nodi di terzo livello, che rappresentano le parole; ogni nodo di parola ha nodi di quarto livello, che rappresentano i singoli caratteri. Ad ogni nodo di ciascun livello sono associate diverse informazioni, tra cui sono da annoverare la posizione, le dimensioni e la struttura della regione corrispondente: diventa in tal modo possibile non solo ricostruire l'intera pagina o sue porzioni logiche con minima perdita di informazione, ma anche individuare relazioni geometriche e posizionali tra le varie regioni.
L'algoritmo che proponiamo per il processo di segmentazione della pagina è una variante di quello descritto al la Sez. 4, che prevede l'identificazione delle componenti connesse presenti nella pagina e l'elaborazione delle coordinate dei loro centri di massa mediante la trasformata di Hough; in questo come in altri casi, abbiamo ragione di ritenere che un'oculata scelta dell'implementazione della trasformata di Hough possa ridurre in maniera significativa i tempi di elaborazione necessari. A questo fine, sono in corso esperimenti per determinare i valori ottimali dei parametri della trasformata che possano garantire una segmentazione veloce e nello stesso tempo affidabile.
Le regioni della pagina classificate come grafiche vengono estratte dall'immagine e memorizzate su file in formato raster ovvero, a scelta dell'utente, in formato compresso. In entrambi i casi, saranno disponibili delle utility in grado di trasformare il formato scelto in uno dei formati grafici standard di mercato (Halo, TIFF, PCX, etc.), affinché l'utente possa intervenire in editing sulle informazioni estratte, ovvero le possa riutilizzare nell'ambito di pacchetti commerciali di word processing o di desktop publishing.
Tutte le regioni grafiche identificate vengono sottratte dall'immagine della pagina, in modo che vi rimangano presenti solo le regioni classificate come contenenti testo, riducendo così -- di solito in maniera considerevole -- la quantità di pixel da sottoporre ad ulteriori elaborazioni. E' il caso di osservare, anche con riferimento ai problemi esposti alla Sez. 6, come l'algoritmo di segmentazione proposto classifichi anche le sottolineature come elementi grafici, e sia quindi in grado di eliminarne gli effetti ancor prima che il testo venga analizzato come tale.
La capacità di riprodurre fotografie riprodotte sul documento è fortemente correlata alle prestazioni dello scanner. In generale, gli scanner usati nei sistemi OCR riproducono in maniera insoddisfacente le fotografie, poiché l'operazione di sogliatura dell'immagine comporta la perdita dei livelli di grigio; il problema può essere superato solo utilizzando uno scanner multilivello, ma la quantità di informazioni da processare diventerebbe allora talmente alta da compromettere seriamente la velocità complessiva del sistema.
Avviene d'altra parte in molte circostanze (come ad esempio nei quotidiani), che i vari livelli di grigio delle fotografie vengano resi sulla pagina mediante retinatura, o halftoning, cioè come densità variabile di pixel bianchi o neri. E' chiaro che in casi del genere lo scanner sarà in grado di trattare correttamente le corrispondenti regioni grafiche, e il sistema sarà di conseguenza in grado di identificarle e di archiviarle senza alcuna perdita di informazioni.
I disegni presenti sulla pagina (figure, grafici, etc.) vengono trattati esattamente come nel caso delle fotografie retinate: la regione viene interpretata come grafica (a meno delle informazioni alfanumeriche presenti in essa) e memorizzata su file in formato raster o compresso eventualmente convertibile in uno dei formati commerciali standard. E' possibile in tal caso prevedere una utility accessoria del sistema che consenta la vettorizzazione dell'immagine e la sua conversione in diversi formati commerciali standard per la manipolazione di grafica del tipo detto line-art (AutoCad DXF, HPGL, etc.).
In molti tipi di documenti, il testo è organizzato su più colonne, e la loro identificazione automatica comporta diversi problemi. Una volta eseguita la separazione testo/grafica ed eliminate dall'immagine base le aree classificate come grafica, quel che rimane sono soltanto caratteri o pattern che verranno in ogni caso interpretati come caratteri. Se a questo punto si opera su una versione dell'immagine a risoluzione ridotta, il problema delle colonne può essere affrontato sotto l'aspetto statistico, nel senso che è possibile identificare regioni della pagina con densità diverse dei pixel neri, quindi con statistiche diverse a seconda che contengano testo di vari tipi oppure sfondo. Con un tale approccio, l'immagine residua della pagina viene segmentata in regioni aventi statistica costante, e diventa così possibile isolare colonne di testo aventi forma anche irregolare, titoli di giornale, e così via. Sono attualmente in corso vari esperimenti per verificare la correttezza di tale ipotesi e per determinare le prestazioni di vari algoritmi tratti dalla letteratura e di numerose loro varianti.
Le informazioni ricavate dalle componenti connesse usate nella separazione testo/grafica e dalla trasformata di Hough dei loro centri di massa possono essere riutilizzate per definire l'orientamento delle righe di testo in una data regione; inoltre, se la pagina non è stata sottoposta a correzione di tilt, o se il testo della regione non è orientato orizzontalmente, le medesime informazioni possono essere utilizzate per la compensazione locale dell'eventuale tilt. In ogni caso, il risultato di queste operazioni è una serie di righe di testo aventi tutte lo stesso orientamento orizzontale, che possono pertanto essere isolate l'una dall'altra.
L'algoritmo più efficiente per questa ulteriore segmentazione sembra essere quello che fa uso delle proiezioni orizzontali (Sez. 6), con l'eventuale ricorso ad un supplemento di informazioni relative alla derivata prima del profilo delle proiezioni. Un algoritmo del genere ha l'ulteriore vantaggio di fornire dati non solo sulla presenza e sulla posizione di una riga di testo, ma anche sulla localizzazione delle quattro linee fondamentali della riga (Fig. 27). Un algoritmo alternativo per l'estrazione di queste quattro linee fondamentali, sulle cui prestazioni sono in corso esperimenti, usa ancora la trasformata di Hough sui punti appartenenti ai bordi superiore e inferiore dei caratteri.
|
||
|
Una volta isolata la singola riga di testo, il problema successivo è la separazione delle singole parole. Le componenti connesse ricavate nel corso della segmentazione della pagina possono anche in questo caso essere imediatamente riutilizzate per la costruzione di un grafico della distribuzione delle distanze tra due componenti connesse consecutive giacenti su una medesima riga di testo. Tale distribuzione sarà in generale bimodale, con una concentrazione di valori corrispondente alla distanza tra caratteri appartenenti alla stessa parola e una diversa concentrazione di valori corrispondente alla distanza tra parole. E' possibile dunque, facendo ricorso a tecniche standard, determinare una soglia ottimale per la separazione dei due picchi e per la conseguente discriminazione delle parole.
Le componenti connesse portano in sé le informazioni necessarie per la segmentazione delle parole in caratteri. Tuttavia, essendo questa una fase particolarmente critica per il buon esito dell'intero processo di lettura, sembra ragionevole usare in parallelo un algoritmo diverso; la tecnica che riteniamo migliore per questo scopo sembra quella descritta in (Kahan et al., 1987), dove viene usato l'istogramma delle proiezioni verticali dei pixel e la sua derivata prima.
A questo punto siamo prossimi alla fase centrale di tutto il processo, la classificazione del singolo carattere; deve però essere chiaro che, per conseguire prestazioni omnifont con minimi tassi di errore, il pattern relativo deve essere preventivamente sottoposto ad un certo numero di pre-elaborazioni.
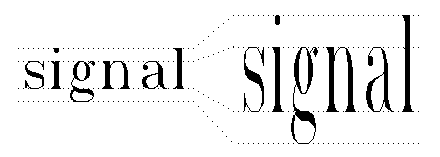
Un primo trattamento consiste nel thinning, con lo scopo di eliminare l'influenza dello spessore dei tratti del carattere e lasciare solamente informazioni sulla forma essenziale del pattern. Una seconda operazione, altamente raccomandabile, consiste nell'eliminazione dello skew (Fig. 28), che può essere realizzata con una semplice trasformazione geometrica del tipo:
x' = x + ly
y' = y
|
||
|
La costante l da usare nella trasformazione può essere valutata mediante la tecnica dei momenti geometrici, facendo in modo da portare sempre allo stesso valore i momenti di un certo ordine (Casey, 1970).
Il terzo ed ultimo tipo di pre-elaborazione consiste nel normalizzare le dimensioni del pattern in modo che esso risulti inscritto in un rettangolo di dimensioni predeterminate, nell'ambito del quale le quattro linee fondamentali citate sopra giacciano in posizioni fisse (Fig. 29); questo tipo di normalizzazione risulta sia stato preso molto raramente in considerazione nella letteratura sul riconoscimento di caratteri, e tuttavia riteniamo che essa sia in grado di eliminare alla radice un gran numero di ambiguità che si possono presentare nella classificazione (come ad esempio, la distinzione tra o minuscola e O maiuscola).
|
||
|
Quando ad altri tipi di pre-elaborazione, esperimenti preliminari da noi eseguiti sull'impiego della trasformata di Mellin (Casasent & Psaltis, 1977; Wechsler & Zimmermann, 1988) per la normalizzazione del pattern hanno dato risultati abbastanza interessanti, sebbene la quantità di operazioni necessarie sia relativamente elevata.
Una volta normalizzato, il pattern di un singolo carattere può infine essere sottoposto a classificazione. Abbiamo attualmente in corso diversi esperimenti per determinare quale delle seguenti procedure di classificazione consenta di ottenere i migliori risultati:
Gli esperimenti in corso tendono a verificare sia l'affidabilità della classificazione, soprattutto per quanto concerne font inusuali e pattern fortemente rumorosi, sia la complessità computazionale necessaria. E' inoltre risaputo che la forma dei caratteri latini normalmente utilizzati nei documenti può speso dar luogo ad ambiguità tali che è spesso illusorio pretendere che possano essere risolte da classificatori operanti senza informazioni dal contesto (Kahan et al., 1987), e che in casi del genere la soluzione migliore è quella di utilizzare regole ad hoc. In molti casi i nostri esperimenti hanno confermato questa tesi, e siamo portati a concludere che, sebbene la soluzione di tali ambiguità non sia impossibile da ottenere da un classificatore context-free, tuttavia la complessità computazionale che ne deriverebbe sarebbe talmente elevata da comportare senza alcun dubbio tempi di elaborazione inaccettabilmente lunghi.
Qualunque sia la qualità e la complessità del classificatore, non è ragionevole fare affidamento su un tasso di riconoscimento del 100%; è indispensabile quindi prevedere anche una fase di post-elaborazione sia per la correzione di eventuali errori di classificazione, sia per la definizione dei caratteri classificati come non riconoscibili.
Un algoritmo abbastanza semplice da implementare e di efficienza apparentemente buona sembra quello descritto in (Kahan et al., 1987). Quanto al dizionario di riferimento da utilizzare come supporto all'algoritmo, riteniamo che sia indispensabile l'uso di un dizionario statico, precostituito per ogni lingua usata nei testi trattati dal sistema, e che sia altrettanto importante il ricorso ad una serie di dizionari ausiliari dinamici gestiti dall'utente secondo le proprie esigenze, che contengano termini specializzati, nomi di persone, acronimi etc., ossia vocaboli non contenuti nei normali dizionari ma che appaiono di frequente nei testi specifici trattati dall'utente.
Un certo grado di verifica sintattica è poi comunque necessario, dal momento che si verificano con frequenza situazioni in cui una parola non può essere correttamente ricostruita senza far riferimento ad altre parole contigue. Un esempio tipico è dato dalle parole che vengono spezzate a fine riga, e che solo in questa fase di post-elaborazione possono essere adeguatamente ricomposte. Un altro esempio di utilità della post-elaborazione è dato dalla ristrutturazione automatica di un articolo di giornale nelle sue varie colonne di testo e nel suo titolo, operazione a cui possono essere di grande ausilio le informazioni di posizionamento associate alle regioni di testo corrispondenti nella struttura ad albero della pagina. Ad ogni modo, la casistica di questa categoria di interventi non appare molto vasta, e riteniamo pertanto che la struttura del verificatore sintattico possa essere impostata con molta semplicità e le operazioni necessarie possano risultare molto rapide.
Un caso speciale di post-elaborazione è la generazione dello stylesheet, o foglio di stile, che contiene i dati rilevanti sulla struttura stilistica del testo; le dimensioni dei caratteri (corpi) e le loro varianti stilistiche (grassetto, corsivo, etc.) possono ad esempio essere ricavate dall'analisi del pattern dei caratteri, mentre il tipo e l'entità della marginatura oppure le eventuali giustificazioni del testo sono tutte informazioni che possono essere dedotte dalla posizione delle righe di testo entro le rispettive regioni; le sottolineature possono essere localizzate confrontando la posizione di componenti connesse orizzontali lunghe e strette rispetto alla posizione di porzioni di testo, e così via. Tutte queste informazioni sono di solito irrilevanti nella lettura di un testo, ma possono assumere una certa importanza quando il testo estratto debba essere poi inserito in un word processor o in un desktop publisher, poiché l'utente viene in tal modo liberato dalla necessità di doverle introdurre manualmente confrontando continuamente il documento originale. In definitiva, la maggior parte dei dati stilistici relativi al documento può essere ricavata riutilizzando nella maniera più opportuna una serie di informazioni già esistenti nella struttura di dati che descrive la pagina, e traslandole quindi nel formato richiesto dal pacchetto applicativo preferito dall'utente.
Le fasi di post-elaborazione comportano essenzialmente ricerche esaustive su una gran quantità di dati più o meno strutturati, e come tali sono meglio implementate sul calcolatore ospite anziché sulla Processing Unit. Come vedremo tra breve, questa soluzione consente di aumentare il throughput del sistema mediante un'opportuna assegnazione dei vari compiti alla Scanner Interface, alla Processing Unit e al calcolatore ospite.
Al completamento di tutte le operazioni descritte, la struttura di dati ad albero che descrive il documento viene nuovamente esplorata al fine di ricostruire le informazioni testuali estratte dalla pagina e di evidenziarne le relazioni reciproche, e per generare finalmente i corrispondenti file di uscita nel formato che l'utente aveva selezionato nel corso della fase di setup del sistema. Assieme ai file di output, viene anche generato un file contenente gli opportuni puntatori agli errori che il sistema è stato in grado di rivelare ma non di correggere, in modo che l'utente venga messo in condizioni di ricostruire le condizioni necessarie alla loro correzione nella eventuale fase di intervento manuale.
Come accennato in precedenza, il sistema di lettura descritto viene implementato su un calcolatore PC-compatibile, equipaggiato con due schede appositamente progettate. Tale soluzione può ovviare a tutta una serie di inconvenienti che si possono così sintetizzare:
Per accelerare al massimo le operazioni necessarie nelle varie fasi del processo di lettura, riteniamo dunque indispensabile accoppiare al PC due schede periferiche specializzate:
Oggigiorno sono disponibili DSP estremamente veloci, con ciclo di macchina che può scendere anche fino ai 60 nsec, in grado di eseguire la gran parte delle istruzioni in un solo ciclo di macchina raggiungendo così throughput di decine di MIPS2 con accesso agevole e veloce a banchi di memoria anche di parecchi megabyte. Diversi DSP sono inoltre in grado di eseguire operazioni aritmetiche (somme, sottrazioni, moltiplicazioni) floating point in uno o due cicli di macchina, e risultano sotto questo aspetto particolarmente efficienti nell'esecuzione di operazioni di tipo vettoriale come sono quelle richieste nell'implementazione software di reti neurali. La precisione e la dinamica dei formati floating-point da 32 o 64 bit utilizzati nei DSP non raggiungono naturalmente quelle di un coprocessore matematico del tipo 80x87, ma sono di gran lunga sufficienti per le operazioni richieste dal sistema OCR.
La disponibilità delle due schede periferiche consente inoltre di partizionare il processo di lettura in modo particolarmente efficiente e di distribuirlo opportunamente sulle varie risorse computazionali presenti; difatti, mentre la Scanner Interface acquisisce e pre-elabora l'immagine di un documento, la Processing Unit può elaborare il documento precedente e il PC ospite può post-elaborare un documento ancora precedente. La sovrapposizione (overlapping) nel tempo delle tre fasi consente in primo luogo di utilizzare al massimo le risorse computazionali disponibili, e in secondo luogo di conseguire una velocità globale di elaborazione virtualmente quasi triplicata.
La progettazione ad hoc delle due schede periferiche consente di definirne la struttura in base alle reali esigenze del sistema, e dà la possibilità di utilizzare, soprattutto nella Processing Unit, i chip neurali che fra non molto tempo dovrebbero cominciare a diffondersi sul mercato. Infine, l'assegnazione della maggior parte del carico computazionale alle due schede dedicate implica in primo luogo che la velocità globale del sistema può essere resa largamente indipendente dalla potenza del calcolatore ospite, e in secondo luogo che il potenziale cliente non si trova necessariamente costretto ad acquistare un sistema completo, ma ha invece una valida e interessante alternativa nell'espansione delle capacità di un sistema già esistente mediante l'acquisto e l'installazione delle due schede dedicate e del relativo software di controllo.
Note
(1) 1 Kflops = 1000 operazioni
floating point al secondo.
(2) 1 MIPS = 1 milione di istruzioni
per secondo.
|
|||||||
© 1997-2003 Paolo Marincola (Rome, Italy)
e-mail: pmaNOSPAM@acm.org (eliminare
i caratteri "NOSPAM" per ottenere l'indirizzo esatto)
Commenti, osservazioni e suggerimenti sono estremamente graditi.
Last revised: 2003-11-09 00:30