Architetture RISC |
|
È noto che ad una progressiva diminuzione dei costi dell'hardware abbia corrisposto, in maniera sempre più evidente nel corso degli ultimi anni, un corrispondente aumento dei costi del software, dovuti ad una serie di ragioni sulle quali non è qui il caso di scendere in dettaglio. Il costo maggiore nel ciclo di vita di un sistema è così da ascrivere al software, non all'hardware; accanto a questa situazione, assume notevole importanza anche il problema dell'affidabilità del software, dal momento che sia in programmi di sistema che in procedure applicative non è raro imbattersi in errori (bugs) di programmazione anche dopo anni di esercizio.
In questo contesto, i ricercatori e le industrie hanno reagito sviluppando linguaggi di programmazione ad alto livello (High-Level Languages, HLL) sempre più potenti e complessi (si pensi all'evoluzione dal Fortran all'Ada), con l'obiettivo dichiarato di consentire al programmatore una sempre maggiore concisione nell'espressione degli algoritmi, di svincolarlo dai dettagli di implementazione e di supportarlo nella maniera più naturale possibile con l'impiego di tecniche di programmazione strutturata.
Tuttavia, questa soluzione ha ulteriormente aggravato il cosiddetto gap semantico, cioè la differenza tra le funzioni utilizzabili all'interno di un linguaggio ad alto livello e quelle messe a disposizione dall'architettura della CPU; le relative conseguenze si sono manifestate in una sempre minore efficienza di esecuzione dei programmi, in una crescente dimensione del codice generato dai compilatori e in una sempre maggiore complessità dei compilatori stessi. Nel tentativo di contrastare queste tendenze, i progettisti hanno allora concepito architetture comprendenti vasti set di istruzioni, decine di modi di indirizzamento diversi e funzioni sempre più complesse implementate in hardware. In base a questa linea di tendenza, la complessità crescente del set di istruzioni dovrebbe consentire di:
Nel frattempo, tuttavia, venivano portati a conclusione un certo numero di studi rivolti a determinare alcuni parametri statistici relativi al codice generato da programmi scritti in linguaggi ad alto livello (che indicheremo nel seguito per brevità programmi HLL); i risultati ottenuti sono stati sorprendenti, tanto da convincere alcuni ricercatori a privilegiare un approccio completamente opposto a quello in voga, consistente cioè nel rendere più semplice l'architettura della CPU, anziché più complessa.
Per comprendere appieno la linea di ragionamento dei sostenitori dell'approccio RISC, cominciamo con una breve revisione delle caratteristiche di esecuzione delle istruzioni. Gli aspetti computazionali a cui in questo contesto siamo interessati sono i seguenti:
Nel seguito di questa sezione riassumeremo i risultati di alcuni studi aventi come oggetto i programmi HLL; è da notare come tali risultati siano basati su misure dinamiche [5] raccolte eseguendo i programmi e contando quante volte nell'unità di tempo si manifesta una certa caratteristica oppure risulta verificata una certa proprietà. Al contrario, le misure statiche, in base alle quali questi conteggi vengono semplicemente eseguiti sul testo sorgente dei programmi, non danno evidentemente alcuna informazione utile sulle prestazioni, poiché non tengono alcun conto di quante volte ciascuno statement viene realmente eseguito (in questa sede, indicheremo con statement un'operazione elementare eseguita sotto un linguaggio ad alto livello, mentre con istruzione indicheremo un'operazione elementare eseguita dalla CPU).
La Tav. I illustra i risultati degli studi citati, per quanto concerne la frequenza relativa di alcune operazioni ad alto livello. Gli statement di assegnazione appaiono predominanti, il che suggerisce che il semplice movimento di dati riveste rilevante importanza; possiamo anche notare una preponderanza di statement condizionali (IF, LOOP), normalmente implementati mediante istruzioni di comparazione e di salto, da cui possiamo dedurre quanto possano essere importanti i meccanismi di controllo della sequenza di istruzioni nella CPU.
| Ricerca | [18] |
[20] |
[30] |
[30] |
[43] |
| Linguaggio | Pascal |
Fortran |
Pascal |
C |
SAL |
| Tipo | (Nota 1) |
(Nota 2) |
(Nota 3) |
(Nota 3) |
(Nota 3) |
| Assegnazioni | 74 |
67 |
45 |
38 |
42 |
| Loop | 4 |
3 |
5 |
3 |
4 |
| Call | 1 |
3 |
15 |
12 |
12 |
| If | 20 |
11 |
29 |
43 |
36 |
| GoTo | 2 |
9 |
-- |
3 |
-- |
| Altre | -- |
7 |
6 |
1 |
6 |
| NOTE (1) Programmi di tipo scientifico. (2) Programmi scritti da studenti. (3) Software di sistema. |
|||||
Questi risultati indicano i tipi di statement che si presentano con maggiore frequenza e che dovrebbero perciò essere supportati in maniera ottimale, ma non danno ancora alcuna informazione sulla distribuzione del tempo di esecuzione tra i vari statement che costituiscono il programma sorgente. In altri termini, dato il codice generato da un compilatore, quali statement nel linguaggio sorgente causano l'esecuzione del maggior numero di istruzioni in linguaggio macchina?
Per rispondere a questo interrogativo, si è proceduto alla compilazione [31] di un certo numero di programmi HLL ed è stato determinato il numero medio di istruzioni di macchina e di riferimenti alla memoria per ciascun tipo di statement; moltiplicando tali valori per la frequenza di apparizione di ciascuno statement, diviene allora possibile ricavare (colonne 2 e 3 di Tav. II) informazioni sul tempo effettivamente utilizzato nell'esecuzione dei vari statement. I risultati suggeriscono che, in un tipico programma HLL compilato per una normale CPU, le operazioni che richiedono il maggior tempo di esecuzione sono le chiamate alle procedure e i relativi ritorni.
Frequenza |
Istruzioni |
Riferimenti |
||||
Pascal |
C |
Pascal |
C |
Pascal |
C |
|
| Assegnazioni | 45 |
38 |
13 |
13 |
14 |
15 |
| Loop | 5 |
3 |
42 |
32 |
33 |
26 |
| Call | 15 |
12 |
31 |
33 |
44 |
45 |
| If | 29 |
43 |
11 |
21 |
7 |
13 |
| GoTo | -- |
3 |
-- |
-- |
-- |
-- |
| Altre | 6 |
1 |
3 |
1 |
2 |
1 |
Nonostante l'importanza dell'argomento, disponiamo di scarsi dati sulla frequenza relativa dei tipi di operandi. Lo studio già citato [31] fornisce i risultati che appaiono in Tav. III, e che mostrano come la maggior parte degli operandi siano semplici variabili scalari (in contrapposizione alle variabili vettoriali, o array, e alle strutture); per di più, oltre l'80% degli scalari sono variabili locali, usate cioè solo temporaneamente all'interno di una singola procedura. E' anche da notare come i riferimenti ad array o a strutture avvengano nella maggior parte dei casi attraverso puntatori, cioè ancora attraverso variabili scalari; queste ultime vengono pertanto ad assumere importanza fondamentale.
| Pascal | C | Media | |
|---|---|---|---|
| Costanti intere | 16 | 23 | 20 |
| Variabili scalari | 58 | 53 | 55 |
| Array e strutture | 26 | 24 | 25 |
Un esame più approfondito del comportamento dinamico dei programmi HLL non può tuttavia prescindere totalmente dall'architettura che li supporta. Sono state svolte delle ricerche tenendo conto anche di questo fattore [21], ed è stato così dimostrato come il numero medio di operandi residenti in memoria a cui ciascuna istruzione fa riferimento è circa 0.5, mentre il numero medio di operandi residenti nei registri è circa 1.4. Questi valori, naturalmente, dipendono fortemente sia dall'architettura della CPU che dal compilatore, ma sono sufficienti a dare un'idea abbastanza precisa della frequenza di accesso agli operandi.
Possiamo dunque concludere che, data la notevole frequenza con cui ha luogo l'accesso agli operandi, l'architettura deve supportare in maniera estremamente efficiente questo tipo di operazione, e deve in particolare essere progettata in maniera da ottimizzare i meccanismi di immagazzinamento e di accesso per le variabili scalari locali.
Abbiamo già visto come le chiamate a procedura e i relativi ritorni rivestano particolare importanza nei programmi HLL, dal momento che l'esecuzione di queste operazioni assorbe la maggior parte del tempo di esecuzione. Una loro implementazione efficiente deve in ogni caso prenderne in considerazione tre aspetti significativi: il numero di parametri passati come argomenti alla procedura, il numero e il tipo di variabili cui la procedura fa riferimento e, infine, la profondità di annidamento (nesting).
In un'apposita indagine su un insieme di programmi [44] è stato accertato non solo che al 98% delle procedure chiamate dinamicamente venivano passati meno di 6 argomenti, ma anche che il 96% di tali procedure faceva riferimento a meno di 6 variabili scalari locali. Risultati analoghi sono stati riportati anche da altre ricerche [19], per cui possiamo senz'altro concludere che il numero di argomenti passati alle procedure è di norma abbastanza basso, e che una proporzione elevata di operandi è costituita da variabili scalari locali.
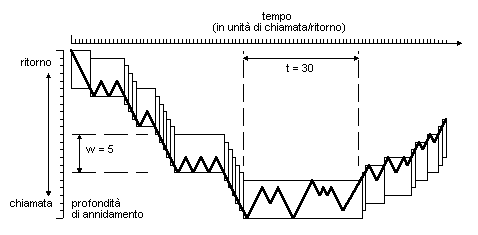
E' stato anche analizzato [19] anche il processo di chiamata a procedura e il corrispondente processo di ritorno, pervenendo alla conclusione che è molto raro trovare lunghe sequenze ininterrotte di chiamate seguite poi dalla corrispondente sequenza di ritorni; appare invece molto più probabile che un programma rimanga confinato all'interno di una "finestra" piuttosto limitata in termini di profondità di annidamento. Questa situazione è illustrata nella Fig. 1, adattata da [29], dove viene esemplificato il comportamento di un programma tipico: la chiamata a una procedura viene rappresentata facendo muovere il grafico verso destra e verso il basso, mentre il ritorno da una procedura viene rappresentato facendo muovere il grafico sempre verso destra ma verso l'alto; nella figura viene anche definita una "finestra" alta 5 livelli di annidamento, posizionata in maniera che soltanto una sequenza di almeno 6 chiamate consecutive o di almeno 6 ritorni consecutivi provochino lo spostamento della finestra stessa. Come è facile vedere, il programma può restare confinato nella finestra per periodi sorprendentemente lunghi. Altre analisi [43] su programmi C, Pascal e Smalltalk hanno ancora mostrato come una finestra di altezza 8 debba essere spostata soltanto nell'1% del totale delle chiamate e dei ritorni.
|
||
|
Dalla discussione finora svolta, possiamo dunque concludere che i tentativi di rendere l'architettura del set di istruzioni sempre più vicina agli statement dei linguaggi ad alto livello possono non costituire un'efficiente strategia di progetto; sembra piuttosto che i linguaggi ad alto livello possano essere più efficacemente supportati laddove vengano ottimizzate le prestazioni di quelle operazioni che richiedono la maggior quantità di tempo di esecuzione. Alla luce di questa conclusione, possiamo dunque sottolineare tre elementi che devono caratterizzare un'architettura RISC:
L'ultimo punto non può essere ancora considerato del tutto ovvio, ma dovrebbe diventarlo alla luce della discussione che segue.
|
|||||||
© 1997-2003 Paolo Marincola (Rome, Italy)
e-mail: pmaNOSPAM@acm.org (eliminare
i caratteri "NOSPAM" per ottenere l'indirizzo esatto)
Commenti, osservazioni e suggerimenti sono estremamente graditi.
Last revised: 2003-12-06 19:47