Architetture RISC |
|
I registri residenti all'interno della CPU sono, come è noto, i dispositivi di memoria più veloci disponibili in un sistema di elaborazione; il metodo più semplice per consentire un rapido accesso agli operandi consiste dunque nel tenerli memorizzati nei registri della CPU. E' indispensabile in tal caso predisporre una strategia che consenta non solo di immagazzinare nei registri gli operandi più frequentemente usati, ma anche di minimizzare le operazioni di trasferimento dati tra i registri e la memoria.
E' possibile individuare al riguardo due approcci fondamentali, uno basato sul software e l'altro sull'hardware. L'approccio software prevede di affidare al compilatore il compito di massimizzare l'utilizzazione dei registri, mediante l'assegnazione dei registri alle variabili maggiormente utilizzate in un dato arco di tempo; come è facile immaginare, questo approccio richiede peraltro il ricorso a sofisticatissimi algoritmi per l'analisi dei programmi. L'approccio hardware, invece, consiste semplicemente nell'usare un numero di registri superiore alla norma, in modo che le variabili possano essere contenute in essi per periodi significativamente più lunghi di tempo.
Per comprendere a fondo il ruolo che i registri giocano nella CPU, dobbiamo avere ben chiare le funzioni a cui la CPU deve assolvere. In particolare, la CPU deve:
Per svolgere queste funzioni, la CPU deve avere la possibilità di immagazzinare temporaneamente vari tipi di informazioni. Non solo, infatti, la CPU deve in qualche modo tener memoria dell'indirizzo dell'ultima istruzione eseguita in modo da sapere da quale indirizzo ricavare la successiva, ma deve anche di solito memorizzare temporaneamente istruzioni e dati mentre una data istruzione è in corso di esecuzione. In altre parole, la CPU necessita di una piccola memoria interna, che per l'appunto è costituita dai registri ad alta velocità.
I registri della CPU possono allora essere assegnati a due grandi categorie:
Va sottolineato come di norma sia difficile trovare una netta separazione tra i registri di queste due categorie: ad esempio, su alcune macchine il Program Counter è visibile all'utente, ma non lo è su altre.
I registri visibili all'utente sono dunque quelli a cui è possibile accedere tramite il linguaggio macchina riconosciuto dalla CPU. In pratica, tutte le odierne CPU mettono a disposizione dell'utente un certo numero di registri visibili, in contrapposizione a certe macchine del passato, ormai essenzialmente obsolete, che disponevano di un solo accumulatore. I registri visibili della CPU possono a loro volta essere così classificati:
I registri per usi generali possono svolgere una varietà di funzioni, a seconda delle esigenze del programmatore. Talvolta il loro uso all'interno del set dell'istruzioni è ortogonale, nel senso che qualunque registro generale può contenere un operando utilizzabile da qualunque istruzione; altre volte, tuttavia, l'architettura della CPU impone determinate restrizioni al loro impiego: per esempio, molte macchine prevedono registri esclusivamente dedicati alle operazioni in virgola mobile.
In taluni casi, poi, i registri per uso generale possono essere anche usati nelle funzioni di indirizzamento (ad esempio, indirizzamento indiretto tramite registro, displacement, etc.). In altri casi, infine, è possibile trovare una separazione più o meno netta tra registri per dati e registri per indirizzi: i registri per i dati non possono essere allora utilizzati nel calcolo dell'indirizzo di un operando, mentre i registri per gli indirizzi possono intervenire in tutti i modi di indirizzamento ovvero essere dedicati soltanto ad alcuni di essi. Come esempi di registri per indirizzi possiamo citare i seguenti:
Vi sono diversi problemi di progetto che a questo punto occorre affrontare. Uno dei più importanti tra questi consiste nella scelta tra l'impiego di registri specializzati ovvero di soli registri per usi generali. Con la prima alternativa, le specifiche di operando possono essere rese implicite all'interno del codice operativo dell'istruzione, con una conseguente economia nel numero di bit necessari ai codici operativi stessi; la seconda alternativa, d'altra parte, concede al programmatore una flessibilità molto maggiore. Non esistono purtroppo criteri che consentano una decisione definitiva, ma sembra che i progettisti si orientino sempre più marcatamente verso l'uso di registri specializzati.
Un altro importante problema di progetto concerne il numero di registri da mettere a disposizione dell'utente, siano essi specializzati o generali. Le decisioni relative influiscono ancora una volta sul progetto del set di istruzioni, poiché un maggior numero di registri implica un maggior numero di bit per la loro identificazione all'interno del codice operativo. Il valore ottimale sembra essere compreso tra 8 e 32 registri [21]: un numero minore di registri implica un maggior numero di riferimenti alla memoria, mentre sembra accertato che un'elevata quantità di registri non riduca apprezzabilmente i riferimenti alla memoria. Va comunque notato che alcuni tra i più recenti sistemi RISC prevedono l'uso di centinaia di registri.
Non va infine trascurata la questione relativa alla lunghezza dei registri: quelli di essi che contengono indirizzi debbono ovviamente avere capacità tale da contenere gli indirizzi più lunghi, mentre i registri dei dati devono poter accogliere i valori relativi alla maggior parte dei tipi di dati specificati. Alcune macchine, tuttavia, ammettono la concatenazione di due o più registri al fine di memorizzare valori di lunghezza multipla di quella fondamentale.
Un'ultima categoria di registri, almeno in parte visibile all'utente, contiene i codici di condizione (flag). I codici di condizione sono dei bit il cui stato è direttamente controllato dall'hardware della CPU in funzione del risultato di determinate operazioni; ad esempio, un'operazione aritmetica può produrre un risultato positivo, nullo o negativo, oppure può generare un overflow: oltre ad immagazzinare il risultato in un registro o nella memoria, l'operazione determina anche lo stato dei codici di condizione. Questi ultimi possono successivamente essere testati nel corso delle istruzioni di salto condizionato, determinando così la scelta tra due o più segmenti di programma in funzione del risultato delle operazioni.
I codici di condizione vengono di norma riuniti in uno o più registri, e fanno così parte di un registro di controllo. In linea generale, alcune istruzioni di macchina consentono all'utente sia di leggere i bit di tale registro mediante riferimenti impliciti, sia, più raramente, di modificarne lo stato.
L'approccio hardware al problema dei registri, introdotto dal Berkeley RISC Group [31], è stato impiegato nel primo prodotto RISC commerciale, il Pyramid [35].
Un vasto set di registri dovrebbe comportare come conseguenza, come abbiamo già accennato, una sostanziale diminuzione degli accessi alla memoria, purché il set di registri sia organizzato in maniera opportuna. Dal momento che gli operandi a cui più frequentemente si fa riferimento sono scalari locali, una strategia apparentemente ovvia prevede la loro memorizzazione all'interno dei registri, riservando eventualmente qualcuno di questi per le variabili globali. Tuttavia, la definizione di locale cambia sia per ogni chiamata a procedura che per ogni ritorno da procedura, operazioni per di più molto frequenti. Immediatamente prima di una chiamata, le variabili locali correnti debbono essere salvate in memoria, in maniera che i relativi registri non solo possano essere utilizzati per il passaggio degli argomenti, ma possano anche essere assegnati alla procedura chiamata per le proprie variabili locali; al ritorno da una procedura, poi, vi deve essere un meccanismo per restituire dei risultati al programma chiamante, e in ogni caso le variabili che erano state salvate in memoria subito prima della chiamata devono essere ricaricate nei registri.
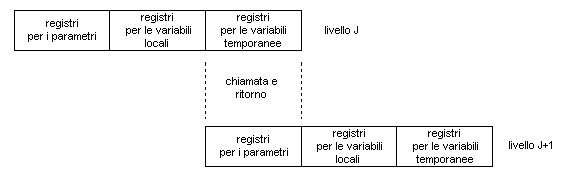
Un'elegante soluzione a questo problema può essere basata su due risultati che abbiamo citato in precedenza: in primo luogo, una tipica procedura richiede solo pochi argomenti ed utilizza un numero ridotto di variabili locali; inoltre, la profondità di attivazione delle procedure fluttua entro un campo di variabilità relativamente ristretto (Fig. 1). Queste proprietà possono essere utilmente sfruttate se si conviene di utilizzare diversi piccoli set di registri, assegnando ciascun set ad una procedura differente. In tal modo, anziché salvare il contenuto dei registri in memoria, una chiamata a procedura non deve far altro che commutare la CPU ad usare una differente "finestra" di registri. Se poi le finestre relative a procedure adiacenti risultano parzialmente sovrapposte, è anche possibile risolvere in maniera estremamente efficiente sia il problema del passaggio degli argomenti che quello della restituzione dei risultati.
Il concetto è illustrato in Fig. 2. Ad ogni istante, soltanto una finestra di registri risulta visibile, e viene indirizzata come se fosse l'unico set di registri disponibile (ad esempio, con indirizzi da 0 ad N-1). La finestra è suddivisa in tre aree di dimensioni fisse:
|
||
|
I registri temporanei assegnati ad una procedura ad un dato livello sono fisicamente gli stessi dei registri dei parametri assegnati ad una procedura al livello inferiore successivo: è facile allora comprendere come questa sovrapposizione consenta il passaggio dei parametri senza alcun reale movimento di dati. Per gestire correttamente tutti i possibili modelli di chiamate e ritorni, tuttavia, il numero delle finestre di registri dovrebbe essere illimitato; è necessario allora utilizzare le finestre disponibili per mantenere soltanto le più recenti attivazioni di procedure, salvare in memoria lo stato completo delle attivazioni meno recenti e ripristinarlo poi quando la profondità di annidamento torna a diminuire. In tal modo l'organizzazione reale del set di registri è quella di un buffer circolare di finestre sovrapposte.
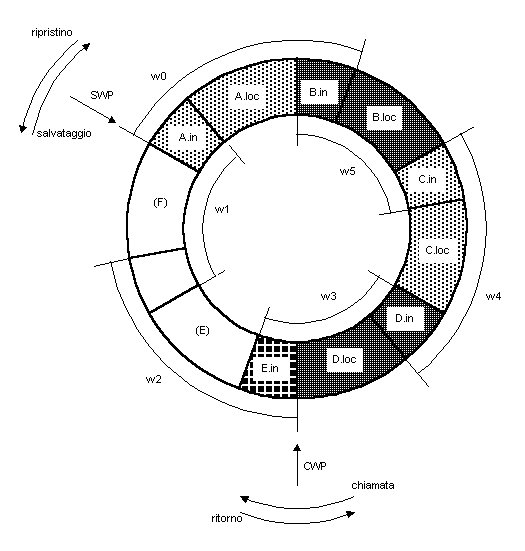
Questa organizzazione appare in Fig. 3, adattata da [19], dove viene esemplificato un buffer circolare di 6 finestre, riempito fino ad una profondità di 4 (la procedura A ha chiamato la procedura B, B ha chiamato C, C ha chiamato D). Il puntatore alla finestra corrente (Current-Window Pointer, CWP) punta alla finestra relativa alla procedura correntemente attiva, che nell'esempio in Fig. 3 è la procedura D; per identificare un registro fisico, i riferimenti ai registri da parte delle istruzioni di macchina sono tutti riferiti a questo puntatore. Il puntatore alla finestra salvata (Saved Window Pointer, SWP) punta invece la finestra più recentemente salvata in memoria.
|
||
|
Se la procedura D adesso chiama la procedura E, gli argomenti da passare ad E vengono immagazzinati nei registri temporanei di D (che costituiscono la sovrapposizione tra le finestre w3 e w4) e il CWP viene avanzato di una finestra. Tuttavia, con lo stato del buffer che ne conseguirebbe, la procedura E non potrebbe a sua volta invocare una procedura F, poiché la finestra di F verrebbe a sovrapporsi alla finestra della procedura A: difatti, quando F comincerebbe a caricare i suoi registri temporanei in preparazione ad una ulteriore chiamata ad una procedura G, il contenuto dei registri di parametro di A verrebbe distrutto. Per ovviare a questo inconveniente, si fa in modo che quando CWP, che viene incrementato (modulo 6) ad ogni chiamata a procedura, diviene uguale a SWP, ha luogo un interrupt e la finestra di A (o più semplicemente le sole sue prime due porzioni, i registri dei parametri e i registri locali) viene salvata in memoria; dopo di che SWP viene incrementato di 1 e la chiamata ad F può procedere. Un interrupt analogo può aver luogo quando, successivamente all'attivazione di F, la catena dei ritorni dalle varie procedure provoca il ritorno dalla procedura B alla procedura A, con CWP che, di volta in volta decrementato, diventa uguale a SWP; la routine di servizio dell'interrupt in questione può allora ripristinare dalla memoria lo stato della finestra di A.
E' chiaro quindi che un set di registri organizzato in N finestre può contenere solo N-1 attivazioni di procedure; tuttavia, non è necessario che il valore di N sia grande. Come abbiamo sottolineato in precedenza, è stato verificato [43] che, con otto finestre, il salvataggio o il ripristino dello stato di una finestra è necessario soltanto nell'1% del totale delle chiamate o dei ritorni. A titolo di esempio, le macchine RISC del Berkeley Group usano 8 finestre da 16 registri ciascuna, mentre il calcolatore Pyramid usa 16 finestre da 32 registri ciascuna.
Lo schema a finestre appena illustrato consente di organizzare in maniera efficiente le operazioni di memorizzazione delle variabili scalari locali nei registri; tuttavia, la memorizzazione delle variabili globali, quelle cioè accessibili da più di una procedura (ad esempio, le variabili COMMON del Fortran), rimane ancora un problema aperto. Una prima possibile soluzione prevede che il compilatore assegni opportune locazioni di memoria alle variabili dichiarate come globali nei linguaggi ad alto livello, in modo che le istruzioni di macchina che fanno riferimento a queste variabili debbano usare operandi con riferimento alla memoria. Un tale meccanismo è relativamente semplice sia sotto l'aspetto dell'hardware che sotto quello del software (ossia del compilatore): in ogni caso, se sono prevedibili accessi frequenti alle variabili globali, questo schema risulta inefficiente.
Una seconda possibile soluzione prevede di incorporare nella CPU un set di registri globali, che dovrebbero essere in numero prefissato e disponibili all'accesso da parte di qualunque procedura; uno schema unificato di numerazione per il loro indirizzamento, poi, potrebbe semplificare il formato dell'istruzione. Ad esempio, i registri numerati da 0 a 7 potrebbero essere dedicati esclusivamente alle variabili globali, mentre i riferimenti ai registri con indirizzo da 8 a 31 potrebbero consentire l'accesso ai registri della finestra corrente. E' chiaro, tuttavia, che in tal modo l'hardware necessario per l'indirizzamento dei registri non può che risultare ulteriormente complicato; per di più, viene ancora lasciato al compilatore il compito di stabilire quale sia l'associazione più opportuna tra le variabili globali e i registri globali disponibili.
Il set di registri organizzato a finestre si comporta come un piccolo ma veloce buffer adibito all'immagazzinamento di un sottoinsieme di variabili che verosimilmente vengono usate più di frequente. Sotto questo aspetto, dunque, il set dei registri opera in maniera abbastanza simile ad una memoria cache: si può allora porre la questione se non sia più vantaggioso e semplice l'utilizzo di una vera e propria memoria cache unita ad un piccolo set di registri tradizionali.
Nella Tav. IV vengono messe a confronto le caratteristiche di questi due approcci. Il set di registri organizzato a finestre contiene tutte le variabili scalari locali (tranne nel raro caso di overflow delle finestre) relative alle N-1 più recenti attivazioni di procedura, mentre la memoria cache è in grado di mantenere soltanto le variabili scalari più recentemente usate. Il set di registri dovrebbe consentire una maggiore velocità di esecuzione, poiché al suo interno sono contenute tutte le variabili scalari locali; d'altra parte, la memoria cache è ingrado di fare uso più efficiente dello spazio di memoria disponibile, poiché essa reagisce dinamicamente alle situazioni contingenti. Inoltre, dal momento che le memorie cache trattano in genere allo stesso modo tutti i riferimenti alla memoria, comprese le istruzioni ed altri tipi di dati, ulteriori aumenti di prestazioni in questi ambiti si possono conseguire con le memorie cache ma non con un set di registri.
Per di più, un set di registri può fare un uso inefficiente dello spazio disponibile, poiché non tutte le procedure hanno in genere necessità di usare tutto lo spazio delle finestre ad esse riservato. D'altra parte la memoria cache è afflitta, per sua parte, da un altro tipo di inefficienza, dovuta al fatto che i dati vengono sempre letti in blocchi: mentre il set di registri contiene solo le variabili correntemente in uso, la memoria cache legge un blocco di dati per volta, un buon numero dei quali non vengono poi utilizzati.
La memoria cache è ovviamente in grado di mantenere sia le variabili globali che quelle locali. In un programma vi sono generalmente molte variabili scalari globali, ma solo una parte di esse viene pesantemente usata [19]: una memoria cache è in grado di scoprire in maniera dinamica queste variabili e di mantenerle al suo interno. Se ad un set di registri organizzato a finestre vengono aggiunti dei registri globali, allora anch'esso potrà contenere alcune variabili scalari globali; rimane però piuttosto difficile per un compilatore determinare quali sono le variabili globali che, essendo le più frequentemente usate, devono risiedere nei registri globali.
In presenza di un set di registri, il movimento dei dati tra i registri e la memoria è essenzialmente determinato dalla profondità di annidamento delle procedure; poiché questa profondità presenta di rado forti oscillazioni, l'uso della memoria viene ad essere relativamente poco frequente. L'organizzazione di tipo set-associative della maggior parte delle memorie cache comporta il rischio che il trasporto di nuovi dati o di nuove istruzioni all'interno del cache provochi la fuoriuscita di variabili frequentemente usate.
Se dovessimo basarci sugli elementi appena discussi, la scelta tra un esteso set di registri organizzato a finestre ed una memoria cache è senza dubbio difficile. Vi è però una particolare circostanza nella quale il set di registri si rivela chiaramente superiore, e che porta a concludere che un sistema basato su memoria cache non può che essere sensibilmente più lento: questa differenza di prestazioni viene alla luce quando i due approcci vengono paragonati sotto l'aspetto dell'overhead dovuto all'indirizzamento.
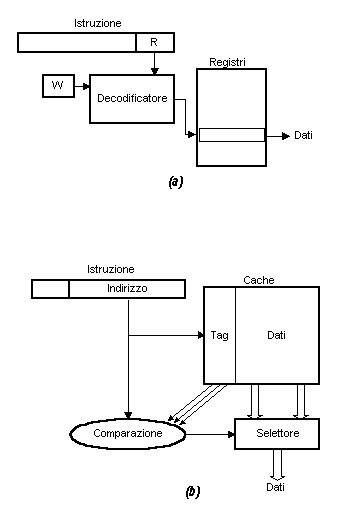
La Fig. 4, adattata da [41], illustra la circostanza citata. Il riferimento ad una variabile scalare locale in un set di registri organizzato a finestre viene effettuato attraverso un numero "virtuale" di registro e un numero di finestra; questi dati richiedono un decodificare relativamente semplice per la generazione della selezione finale di un registro fisico. Per accedere ad una locazione della memoria cache, però, deve in ogni caso essere generato un indirizzo di memoria completo, e la complessità di questa operazione dipende poi dal modo di indirizzamento specificato: se anche la memoria cache fosse veloce quanto il set di registri, il tempo di accesso verrebbe sempre ad essere considerevolmente più lungo. Dal punto di vista delle prestazioni, dunque, è possibile concludere che un set di registri organizzato a finestre è sensibilmente superiore per la manipolazione delle variabili scalari locali; un ulteriore miglioramento si potrebbe poi conseguire aggiungendo una memoria cache da usare solo per le istruzioni.
|
||
|
Supponiamo adesso che sulla macchina RISC in questione sia disponibile solo un piccolo numero di registri (ad esempio, 16 o 32); la responsabilità dell'uso ottimale dei registri è allora delegata unicamente al compilatore. Un programma scritto in un linguaggio ad alto livello non ha ovviamente riferimenti espliciti ai registri, dal momento che i riferimenti alle entità manipolate dal programma sono sempre simbolici: l'obiettivo del compilatore è allora quello di concentrare il maggior numero possibile di elaborazioni al livello dei registri anziché al livello della memoria centrale e di minimizzare nel contempo le operazioni di trasferimento di dati.
La tecnica che di norma si preferisce impiegare è la seguente. Ogni entità del programma che è candidata a risiedere in un registro viene assegnata ad un registro simbolico (o virtuale); il compilatore dovrà allora costruire una associazione (mapping) tra i vari registri simbolici (che sono in linea di principio in numero illimitato) e i registri reali (che sono in numero prefissato). I registri simbolici che in nessun istante vengono utilizzati contemporaneamente possono allora essere assegnati allo stesso registro reale; se in un dato segmento del programma vi sono più registri simbolici attivi che non registri reali, allora alcune delle entità contenute nei registri simbolici vengono assegnate a locazioni di memoria, e si fa poi ricorso ad opportune operazioni di caricamento per posizionare temporaneamente le entità nei registri reali o ad operazioni di immagazzinamento per salvare le entità in memoria quando occorra rendere disponibile i registri reali che le contengono.
Il processo di ottimizzazione consiste dunque essenzialmente nel decidere quali entità debbano essere assegnate ai registri reali in ogni punto del programma. La tecnica più comunemente usata nei compilatori RISC è presa in prestito dalla topologia ed è nota come colorazione di grafi [7] [8] [11].
Dato un grafo costituito da nodi e connessioni, il problema della sua colorazione consiste nell'assegnare dei colori ai nodi in modo che nodi adiacenti abbiano colori differenti, in maniera da rendere minimo il numero di colori necessari. Con alcune lievi varianti, tale problema può essere riportato a quello che il compilatore deve risolvere al momento dell'assegnazione dei registri simbolici ai registri reali disponibili. In primo luogo, il compilatore analizza il programma per costruire un grafo di interferenza dei registri secondo le regole che seguono:
Costruito il grafo di interferenza, il compilatore tenta di colorarlo con N colori, dove N è il numero dei registri reali disponibili. Se il problema di colorazione non può essere risolto, allora le entità associate ai nodi che non possono venir colorati debbono essere collocate in memoria.
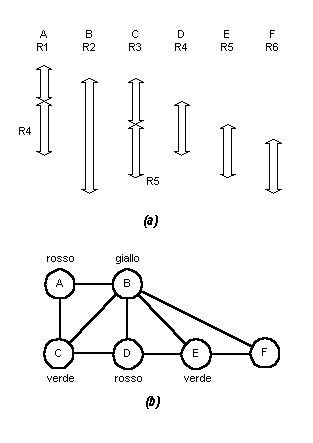
La Fig. 5 riporta un semplice esempio del processo descritto. Immaginiamo che un programma con sei registri simbolici debba essere compilato su una macchina con tre registri attivi. La Fig. 5a mostra la sequenza temporale dell'attività di ciascun registro simbolico, e la Fig. 5b mostra il grafo di interferenza dei registri con una possibile colorazione con tre colori: un registro simbolico, F, rimane non colorato e l'entità ad esso corrispondente dovrà essere mantenuta in memoria anziché nel set di registri.
|
||
|
|
|||||||
© 1997-2003 Paolo Marincola (Rome, Italy)
e-mail: pmaNOSPAM@acm.org (eliminare
i caratteri "NOSPAM" per ottenere l'indirizzo esatto)
Commenti, osservazioni e suggerimenti sono estremamente graditi.
Last revised: 2003-12-06 19:47