Il pipeline nelle CPU RISC
Il pipelining delle istruzioni, che è una delle tecniche tradizionalmente adottate per
aumentare le prestazioni di un processore, può essere usato con efficienza ancora
maggiore, come vedremo, in presenza di un set ridotto di istruzioni; al fine di
illustrarne la significatività su una macchina RISC, cominciamo con una discussione
generale.
Strategia di pipelining
Il pipeline delle istruzioni è per molti versi simile ad una catena di montaggio in un
impianto di produzione. La catena di montaggio trae vantaggio dal fatto che il prodotto
deve passare attraverso varie fasi di produzione: se il processo di produzione è
organizzato sotto forma di catena di montaggio, diventa possibile operare simultaneamente
su molte unità di prodotto, ciascuna in una fase diversa di lavorazione. Un processo del
genere viene anche detto pipeline, dato che, in maniera analoga a quanto accade in
una condotta, è possibile accettare nuovo materiale in ingresso ad una estremità prima
ancora che i materiali precedentemente accettati appaiano in uscita all'altra estremità.
Questo concetto può essere applicato al flusso delle istruzioni eseguite da una CPU
non appena si riconosca che l'esecuzione di un'istruzione implica in realtà un certo
numero di fasi successive. In prima approssimazione, supponiamo che l'elaborazione di
un'istruzione possa essere suddivisa in due sole fasi: il fetch e l'esecuzione vera e
propria. E' chiaro che, durante la seconda fase, vi sono in generale intervalli di tempo
nei quali non viene compiuto alcun accesso alla memoria centrale: è allora possibile
sfruttare questi intervalli di tempo per procedere al fetch dell'istruzione successiva, in
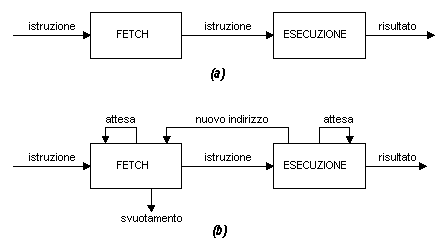
parallelo quindi con l'esecuzione di quella corrente. Questo concetto è illustrato in Fig. 7a, dove il pipeline ha due stadi indipendenti, il primo
dei quali esegue il fetch di un'istruzione e ne memorizza temporaneamente il codice
operativo in un buffer. Quando il secondo stadio si rende libero, il primo stadio gli
trasferisce l'istruzione attualmente memorizzata nel buffer; così, mentre il secondo
stadio sta eseguendo le operazioni richieste dall'istruzione, il primo stadio può
sfruttare un qualunque ciclo di memoria inutilizzato per eseguire il fetch e la
memorizzazione della prossima istruzione. Un processo del genere è detto prefetch
dell'istruzione, o overlap del fetch.
|
| Fig. 7 |
Pipeline di istruzioni a due stadi: (a) struttura semplificata,
(b) struttura espansa. |
|
Dovrebbe essere sufficientemente chiaro che questo processo è in grado di accelerare
l'esecuzione dell'istruzione; in particolare, se il fetch e l'esecuzione dell'istruzione
avessero entrambi la stessa durata, allora il tempo totale di ciclo di un'istruzione
dovrebbe risultare dimezzato. Tuttavia, se esaminiamo con maggior attenzione la struttura
del pipeline (Fig. 7b), possiamo comprendere come vi siano
almeno due ragioni che rendono irragionevole aspettarsi un tale raddoppio della velocità
di esecuzione:
- Il tempo di esecuzione dell'istruzione è in genere più lungo del tempo di fetch.
Durante la fase di esecuzione, difatti, può esser necessario leggere e/o scrivere alcuni
operandi, come pure può esser necessario procedere ad elaborazioni relativamente
complesse; di conseguenza, la fase di fetch potrebbe dover attendere un certo tempo prima
di poter svuotare il suo buffer.
- Un'istruzione di salto condizionato rende impredicibile l'indirizzo dell'istruzione
della quale eseguire il successivo fetch. In una tale situazione, la fase di fetch non
può procedere fino a che non riceve l'indirizzo dell'istruzione successiva dalla fase di
esecuzione; la fase di esecuzione, a sua volta, dovrebbe poi restare inattiva finché non
venga completato il fetch dell'istruzione successiva.
Il tempo sprecato per la seconda delle ragioni esposte può essere limitato facendo
ricorso ad una qualche congettura su quello che sarà l'indirizzo dell'istruzione
successiva. Una semplice regola potrebbe essere la seguente: quando un'istruzione di salto
condizionato viene trasmessa dallo stadio di fetch a quello di esecuzione, lo stadio di
fetch esegue comunque il fetch dell'istruzione che nella memoria segue
all'istruzione di salto. In tal modo, se il salto non deve essere eseguito, se cioè la
condizione di salto risulta falsa, non viene sprecato alcun tempo; se invece il salto deve
essere eseguito, se cioè la condizione di salto risulta vera, allora l'istruzione il cui
fetch è già stato eseguito deve essere scartata, e si deve procedere al fetch di una
nuova istruzione.
Benché questi fattori riducano la potenziale efficacia del pipeline a due fasi, è
indubbio che la velocità totale di esecuzione viene accresciuta. Si può tuttavia
conseguire una velocità ancora maggiore se il pipeline viene strutturato su un numero
maggiore di stadi. Consideriamo l'elaborazione di un istruzione come suddivisa nelle fasi
seguenti:
- Fetch dell'istruzione (FI), che consiste nel determinare (eventualmente mediante
congetture appropriate) l'istruzione successiva e nel caricarla in un buffer.
- Decodifica dell'istruzione (DI), che consiste nel determinarne il codice
operativo e le specifiche degli operandi.
- Calcolo degli operandi (CO), o più precisamente dell'indirizzo effettivo di
ciascun operando sorgente; questa fase può naturalmente comprendere varie forme di
calcolo di indirizzi (con displacement, indiretto tramite registri, indiretto, etc.).
- Fetch degli operandi (FO), che consiste nell'estrazione degli operandi dalla
memoria. Tale fase, ovviamente, è superflua se gli operandi richiesti risultano già
contenuti nei registri.
- Esecuzione dell'istruzione (EI), che comprende sia l'esecuzione delle operazioni
richieste dall'istruzione sia la memorizzazione degli eventuali risultati nella locazione
dell'operando destinazione specificata.
Con una decomposizione del genere, le varie fasi diventano di durata pressoché
identica. A titolo illustrativo, assumiamo uguale durata per ciascuna fase e supponiamo
inoltre che, tra tutti gli stadi che richiedano un accesso alla memoria, soltanto uno
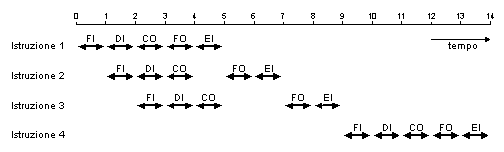
possa essere attivo ad un dato istante. La Fig. 8 mostra
allora come, con l'introduzione di un pipeline a 5 stadi, il tempo di esecuzione di una
sequenza di 4 istruzioni possa essere ridotto da 20 a 14 unità di tempo. Si osservi in
proposito che lo stadio FI richiede sempre un accesso alla memoria; gli stadi FO ed EI
possono o meno richiedere accessi alla memoria, ma il diagramma è basato sull'assunzione
che lo facciano.
|
| Fig. 8 |
Diagramma temporale delle operazioni in un pipeline. |
|
Anche con una tale struttura del pipeline, diversi fattori concorrono a ridurre i
miglioramenti teorici nelle prestazioni. Se le cinque fasi non hanno la stessa durata, vi
saranno dei tempi di attesa nei vari stadi del pipeline, in maniera analoga a quanto visto
in precedenza. Un'istruzione di salto condizionato, poi, può comportare
l'inutilizzabilità di diversi fetch di istruzioni già eseguiti. Infine, un evento
analogo al salto condizionato ma del tutto imprevedibile è costituito dall'arrivo di un
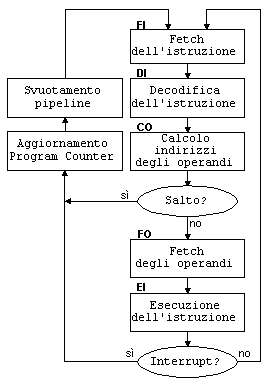
interrupt. In Fig. 9 è indicata la logica necessaria
all'interno di un pipeline per tener conto sia dei salti che degli interrupt.
|
| Fig. 9 |
Pipeline in una CPU a 5 stadi. |
|
Inoltre, nella struttura a cinque stadi sorgono altri problemi che non apparivano nella
struttura a due soli stadi. Ad esempio, la fase CO può dipendere dal contenuto di un
registro che potrebbe venir modificato da un'istruzione precedente che non abbia ancora
completato il suo percorso nel pipeline. Altri conflitti del genere possono poi sorgere
tra la memoria e i registri; in ogni caso, il sistema deve contenere logiche opportune sia
per gestire correttamente questo tipo di conflitti, sia per migliorare l'efficienza del
pipeline. Ad esempio, se una fase EI non richiede accessi alla memoria, allora in
parallelo ad essa può essere eseguita un'altra fase che richieda l'accesso alla memoria e
che sia relativa ad un'altra istruzione.
La discussione precedente sembrerebbe suggerire che la velocità di esecuzione è tanto
maggiore quanto maggiore è il numero di fasi nel pipeline; tuttavia, vi sono due fattori
che operano contro una simile conclusione:
- In corrispondenza a ciascuna fase del pipeline, è sempre presente un certo overhead nel
movimento di dati da un buffer all'altro, come pure nell'esecuzione delle varie operazioni
di preparazione e di trasferimento dei dati. Tali overhead possono prolungare
sensibilmente il tempo di esecuzione totale di una singola istruzione, e questo a sua
volta può provocare rallentamenti significativi quando il modello idealizzato del
pipeline non può essere applicato per via dei salti e/o di particolari dipendenze da
accessi alla memoria.
- La quantità di logica di controllo necessaria per tenere sotto controllo le dipendenze
dalla memoria e dai registri e per ottimizzare l'uso del pipeline cresce enormemente con
il numero di fasi, il che può portare ad una situazione in cui la logica di controllo
della comunicazione tra i vari stadi viene ad essere più complessa degli stadi che
debbono essere controllati.
Possiamo concludere affermando che il pipeline delle istruzioni è senza alcun dubbio
una potente tecnica per aumentare le prestazioni di una CPU, ma richiede un progetto molto
accurato per poter raggiungere risultati ottimali con una ragionevole complessità.
I salti
Uno dei principali problemi che si presentano nel progetto del pipeline delle
istruzioni consiste nell'assicurare un flusso stabile di istruzioni agli stadi iniziali
del pipeline. Come abbiamo visto, la continuità del flusso delle istruzioni viene
interrotta principalmente dalle istruzioni di salto condizionato, dato che è impossibile
determinare se il salto verrà eseguito o meno fino a quando l'istruzione non viene
effettivamente eseguita. Riassumiamo brevemente qui di seguito alcuni degli approcci più
comuni con cui viene affrontato tale problema.
- Flussi multipli (multiple streams): In presenza di un'istruzione di salto
condizionato, un normale pipeline deve scegliere, tra due possibili istruzioni successive,
quella della quale eseguire il fetch, e può scegliere in modo errato. Un possibile
approccio consiste nel consentire al pipeline di eseguire il fetch di entrambe le
istruzioni, facendo uso di flussi multipli. Uno degli inconvenienti che si possono
presentare, tuttavia, ha luogo quando ulteriori istruzioni di salto condizionato entrano
nel pipeline attraverso i vari flussi prima che il salto originale sia stato risolto;
tutte queste istruzioni possono allora richiedere dei loro propri flussi multipli, in
quantità totale superiore a quella che può essere supportata dall'hardware.
- Prefetch della destinazione: Quando viene riconosciuta un'istruzione di salto
condizionato, viene eseguito il prefetch della destinazione del salto, in aggiunta al
fetch dell'istruzione successiva a quella di salto. L'istruzione all'indirizzo
destinazione viene quindi salvata fino a quando l'istruzione di salto non viene
completata: se il salto viene eseguito, il prefetch dell'istruzione all'indirizzo
destinazione è già completato.
- Predizione del salto: Si possono usare varie tecniche per predire se un salto
sarà effettuato, basate sull'analisi storica delle esecuzioni precedenti del programma,
oppure su una qualche misura dinamica della frequenza dei salti precedenti.
- Salto ritardato: E' possibile migliorare le prestazioni del pipeline
riorganizzando opportunamente le istruzioni all'interno del programma in modo che
un'istruzione di salto avvenga il più tardi possibile.
I primi tre approcci sono sempre implementati in hardware ed entrano in azione al
momento dell'esecuzione del programma, cioè in run time. L'ultimo approccio è
eseguito al tempo di compilazione (compile time), ed è quello adottato nella
maggior parte dei compilatori RISC.
Il pipeline con istruzioni RISC
Consideriamo ora il pipeline nel contesto di un'architettura RISC. La maggior parte
delle istruzioni sono del tipo registro-registro, ed il ciclo di istruzione ha le seguenti
due fasi:
- I: Fetch dell'istruzione.
- E: Esecuzione. Viene eseguita un'operazione logico- aritmetica con gli operandi
prelevati da registri e il risultato scritto su un registro.
Le istruzioni di lettura (load) dalla memoria e di scrittura (store) in
memoria si articolano invece in tre fasi:
- I: Fetch dell'istruzione.
- E: Esecuzione. Viene calcolato l'indirizzo di memoria.
- D: Memoria. Viene eseguito un trasferimento da registro a memoria oppure da memoria a
registro.
|
| Fig. 10 |
Temporizzazione di un'esecuzione sequenziale. |
|
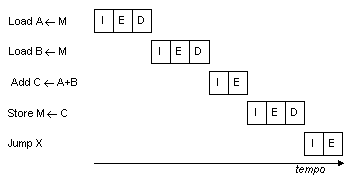
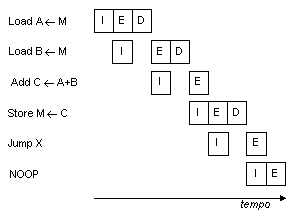
La Fig. 10 mostra la temporizzazione di una sequenza
di istruzioni che non fanno alcun uso di pipeline (le Figg. 10,
11, 12, 13 e 14 sono basate su [39]); chiaramente, questo è un processo molto dispersivo
sotto l'aspetto del tempo di esecuzione. Anche un pipeline semplicissimo può migliorare
le prestazioni in maniera sostanziale; la Fig. 11 mostra
uno schema di pipeline a due stadi, in cui le fasi I ed E di due istruzioni diverse
vengono eseguite simultaneamente: rispetto ad uno schema puramente seriale, questa
struttura può arrivare quasi a raddoppiare la velocità di esecuzione. In realtà, la
velocità massima teorica non può essere raggiunta e mantenuta per via di due fattori.
Per prima cosa, il tacito asunto che abbiamo fatto è che la memoria usata sia a
singola porta, che cioè sia possibile un solo accesso alla memoria per fase, il che
richiede l'inserimento di uno stato di attesa in alcune istruzioni. In secondo luogo, può
sempre intervenire un'istruzione di salto ad interrompere il flusso sequenziale
dell'esecuzione; per affrontare questa situazione con il minimo ricorso all'hardware, il
compilatore o l'assembler possono aggiungere un'istruzione NOOP (No Operation) in
posizione opportuna nella sequenza delle istruzioni.
|
| Fig. 11 |
Temporizzazione di un pipeline a due stadi. |
|
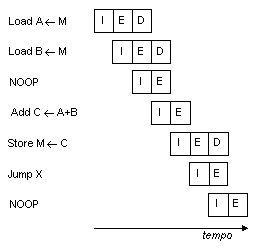
Le prestazioni del pipeline possono essere ulteriormente migliorate se viene impiegata
una memoria a due porte, se cioè sono permessi due accessi alla memoria per
ciascuna fase: la sequenza che ne deriva è illustrata in Fig.
12. Con queste ipotesi, possono essere sovrapposte fino a tre istruzioni
contemporaneamente, e la velocità di esecuzione aumenta così al più di un fattore tre.
Ancora una volta, le istruzioni di salto non consentono di raggiungere la massima
velocità teorica. Si osservi che le dipendenze dei dati producono effetti importanti e
complessi: se un'istruzione ha bisogno di un operando che può essere modificato
dall'istruzione precedente, allora occorre inserire uno stato di attesa, e questo può
farlo automaticamente il compilatore utilizzando un'istruzione NOOP.
|
| Fig. 12 |
Temporizzazione di un pipeline a tre stadi. |
|
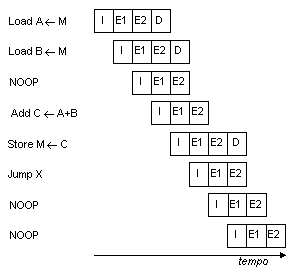
Il pipeline oggetto della discussione precedente lavora al meglio se le tre fasi hanno
approssimativamente la stessa durata. Poiché in genere la fase E coinvolge un'operazione
logico-aritmetica, essa può tuttavia richiedere un tempo maggiore che non le altre fasi.
In tal caso, possiamo suddividere E in due sottofasi:
- E1: Lettura degli operandi dal set di registri.
- E2: Operazione logico-aritmetica e scrittura del risultato nel set di registri.
Per via della semplicità e della regolarità del set di istruzioni, la distribuzione
dei compiti della CPU in presenza di un pipeline a tre o a quattro stadi non è un compito
eccessivamente difficile. La Fig. 13 mostra il risultato
con un pipeline a quattro stadi: adesso possono essere in esecuzione fino a quattro
istruzioni per volta, e la massima velocità potenziale aumenta di un fattore di quattro.
Si osservi ancora l'uso di istruzioni NOOP per ovviare sia ai conflitti derivanti dalle
dipendenze dei dati sia all'interruzione del flusso delle istruzioni dovuto ai salti.
|
| Fig. 13 |
Temporizzazione di un pipeline a quattro stadi. |
|
Ottimizzazione del pipeline
A causa della natura semplice e regolare delle istruzioni RISC, gli schemi di pipeline
si riflettono sempre in una maggiore efficienza di esecuzione. Quando vi siano piccole
variazioni nella durata dell'esecuzione delle varie fasi di un'istruzione, il pipeline
può essere adattato per sfruttare al meglio tali differenze. In ogni caso, abbiamo visto
che le istruzioni di salto e le dipendenze dei dati non consentono mai di raggiungere la
massima velocità teorica di esecuzione.
Tav. VIII
Esempio di salto normale e di salto ritardato
| Indirizzo |
Salto normale |
Salto ritardato |
Salto ritardato
ottimizzato |
| 100 |
LOAD X,A |
LOAD X,A |
LOAD X,A |
| 101 |
ADD 1,A |
ADD 1,A |
JUMP 105 |
| 102 |
JUMP 105 |
JUMP 106 |
ADD 1,A |
| 103 |
ADD A,B |
NOOP |
ADD A,B |
| 104 |
SUB C,B |
ADD A,B |
SUB C,B |
| 105 |
STORE A,Z |
SUB C,B |
STORE A,Z |
| 106 |
|
STORE A,Z |
|
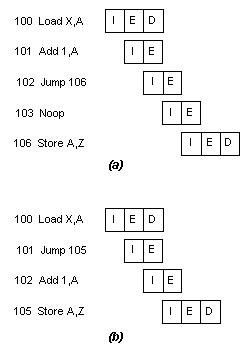
Per ovviare a questi inconvenienti sono state sviluppate alcune tecniche di
riorganizzazione del codice [17]. Consideriamo per prima
cosa le istruzioni di salto. Il salto ritardato, uno dei modi per aumentare
l'efficienza del pipeline, fa uso di un salto che viene eseguito solo dopo l'istruzione
seguente; questa procedura, dall'apparenza piuttosto strana, è illustrata nella Tav. VIII. Nella prima colonna troviamo un normale
programma in linguaggio macchina con istruzioni simboliche; una volta eseguita
l'istruzione 102, la prossima istruzione da eseguire è la 105. Per regolarizzare il
pipeline, dopo questo salto viene inserita un'istruzione NOOP. Tuttavia, è possibile
conseguire un aumento di prestazioni se le istruzioni 101 e 102 vengono scambiate tra
loro. La Fig. 14 mostra il risultato: l'istruzione JUMP
viene estratta dalla memoria prima dell'istruzione ADD. Si noti, comunque, che il fetch
dell'istruzione ADD ha luogo prima che l'esecuzione dell'istruzione JUMP abbia la
possibilità di modificare il Program Counter; in tal modo, la semantica originale del
programma non viene alterata.
|
| Fig. 14 |
Esecuzione del salto ritardato: (a) inserzione di NOOP,
(b) riposizionamento di istruzioni. |
|
Lo scambio di istruzioni può funzionare con successo per salti incondizionati,
chiamate a procedure e ritorni da procedure; per i salti condizionati, tuttavia, questa
tecnica deve essere applicata in maniera molto oculata. Se la condizione che viene testata
ai fini del salto può essere modificata dall'istruzione immediatamente precedente, allora
il compilatore non deve scambiare le istruzioni ma deve inserire, invece, un
istruzione di NOOP. L'esperienza maturata sia sul Berkeley RISC che sull'IBM 801 porta a
concludere che con questa tecnica è possibile ottimizzare la maggior parte dei salti
condizionati [31] [34].
Una tecnica analoga, detta caricamento ritardato (delayed load), può essere
impiegata per le istruzioni di LOAD. Nelle istruzioni di LOAD il registro usato come
destinazione del trasferimento viene per così dire "bloccato" dalla CPU, la
quale prosegue poi con l'esecuzione del flusso di istruzioni finché non incontra
un'istruzione che richiede il contenuto di quel registro; solo a questo punto la CPU deve
aspettare che l'istruzione di LOAD viene completata. Se il compilatore è in grado di
riorganizzare le istruzioni in modo tale che la CPU possa eseguire del lavoro utile mentre
l'istruzione di LOAD è nel pipeline, l'efficienza del sistema viene a crescere
notevolmente.
© 1997-2003 Paolo Marincola (Rome, Italy)
e-mail: pmaNOSPAM@acm.org (eliminare
i caratteri "NOSPAM" per ottenere l'indirizzo esatto)
Commenti, osservazioni e suggerimenti sono estremamente graditi.
Last revised: 2003-12-06 19:47