Architetture RISC |
|
In questa sezione ci rivolgeremo ad alcune tra le caratteristiche generali e le motivazioni alla base di un'architettura con set di istruzioni ridotto. E' opportuno tuttavia premettere una breve discussione delle ragioni e delle aspettative che hanno portato alle architetture contemporanee con set di istruzioni complessi.
Già in precedenza abbiamo notato la tendenza verso set di istruzioni sempre più ricchi e complessi. Due ragioni principali hanno motivato questa tendenza: il desiderio di semplificare i compilatori e il desiderio di migliorare le prestazioni delle CPU. Alla base di entrambe queste motivazioni possiamo senz'altro individuare la transizione dei programmatori verso i linguaggi ad alto livello; gli architetti di sistema hanno di conseguenza tentato di progettare macchine in grado di fornire un sempre maggior supporto a tali linguaggi.
Non è assolutamente possibile sostenere che i progettisti delle macchine CISC abbiano scelto la direzione sbagliata: la tecnologia RISC è relativamente recente, per cui il dibattito RISC-CISC non potrà certamente essere risolto in tempi brevi. In realtà, dal momento che la tecnologia è in continua evoluzione e che le architetture di sistema sono distribuite lungo uno spettro piuttosto che in due nette categorie, sembra inverosimile che si riuscirà mai a risolvere definitivamente una simile questione. Così, i commenti che seguono devono essere semplicemente interpretati sia come puntualizzazione di alcuni potenziali inconvenienti impliciti nell'approccio CISC, sia come elementi per una piena comprensione delle convinzioni dei sostenitori dell'approccio RISC.
La prima delle motivazioni citate, la semplificazione dei compilatori, sembra a prima vista ovvia. Il compito del compilatore consiste nel generare una sequenza di istruzioni di macchina per ciascuna istruzione HLL, e se sono disponibili istruzioni di macchina che rassomigliano alle istruzioni HLL da tradurre, il compito dovrebbe risultare senz'altro semplificato. Questa linea di ragionamento è stata tuttavia contestata dai ricercatori RISC [15] [34] [33]: essi hanno mostrato come le istruzioni di macchina complesse sono spesso difficili da sfruttare, poiché il compilatore deve trovare quei casi che si adattano esattamente al loro costrutto, ovvero adattare ad esse segmenti di programma. Il compito di ottimizzazione assegnato al compilatore per minimizzare le dimensioni del codice generato, per ridurre il numero delle istruzioni eseguite e per sfruttare appieno il pipelining appare dunque molto più difficile con un set di istruzioni complesso: a dimostrazione, gli studi citati in precedenza indicano che la massima parte delle istruzioni generate in un programma compilato è costituita solo da istruzioni relativamente semplici.
L'altra ragione principale citata è l'aspettativa che un set di istruzioni complesso possa consentire di generare programmi più compatti e più veloci. Proviamo allora a prendere in esame entrambi gli aspetti di questa asserzione: che i programmi siano più compatti e che siano eseguiti più rapidamente.
Vi sono naturalmente due vantaggi in un programma più compatto. In primo luogo, poiché il programma richiede meno memoria, diventa possibile realizzare una certa economia nell'impiego di questa risorsa; con le memorie odierne che diventano sempre meno costose, tuttavia, questo vantaggio potenziale diventa sempre meno essenziale. Ancora maggiore importanza assume allora la possibilità che programmi più compatti comportino migliori prestazioni, sia perché una minor quantità di istruzioni implica un minor numero di dati da estrarre dalla memoria nelle fasi di fetch, sia perché, in un ambiente con memoria virtuale, programmi più piccoli occupano meno pagine, riducendo così i page faults.
Questa linea di ragionamento, tuttavia, è ben lontana dal dimostrare che un programma CISC sia più compatto di un corrispondente programma RISC. E' ben vero, difatti, che in molti casi un programma CISC, espresso in linguaggio macchina simbolico (Assembly Language), risulta più corto (costituito cioè da un numero minore di istruzioni) del corispondente programma RISC, ma il numero di bit di memoria realmente impegnati dal programma può non essere significativamente inferiore.
La Tav. V mostra i risultati di tre studi nei quali venivano paragonate le dimensioni di programmi C risultanti dalla compilazione su un certo numero di macchine, tra le quali era compreso il RISC I, dotato di un'architettura con set ridotto di istruzioni. Come è facile vedere, l'economia realizzata nel codice CISC rispetto al codice RISC è minore di quanto ci si potesse aspettare; è anche interessante notare come il codice generato per un VAX-11 è di poco più corto del codice generato per un PDP-11, che ha un set di istruzioni molto meno complesso. Questi risultati sono stati successivamente confermati da alcuni ricercatori dell'IBM [34] quando, indagando sui prodotti della compilazione di un insieme di programmi in linguaggio PL/I, hanno accertato che la dimensione del codice prodotto per l'IBM 801 (una macchina RISC) era addirittura il 90% del codice prodotto per un IBM S/370 (una macchina CISC).
| CPU | 11 programmi [30] |
12 programmi [19] |
5 programmi [16] |
|---|---|---|---|
| RISC I | 1.0 |
1.0 |
1.0 |
| VAX-11/780 | 0.8 |
0.67 |
-- |
| M68000 | 0.9 |
-- |
0.9 |
| Z8002 | 1.2 |
-- |
1.12 |
| PDP-11/70 | 0.9 |
0.71 |
-- |
Questi risultati, benché soprendenti, non possono però essere considerati casuali. Abbiamo già osservato che i compilatori per macchine CISC tendono a favorire le istruzioni più semplici, cosicché la concisione delle istruzioni complesse viene sfruttata solo di rado. Inoltre, la gran quantità di istruzioni su una macchina CISC implica che i loro codici operativi debbano essere piuttosto lunghi in termini di bit. Infine, i RISC tendono a privilegiare i riferimenti ai registri piuttosto che alla memoria; la codifica delle istruzioni relative richiede allora un numero minore di bit per meno bit per la codifica, poiché in esse non deve essere specificato alcun indirizzo di memoria. Un esempio di quest'ultimo effetto appare nella Fig. 6, che verrà illustrata più avanti.
Possiamo così concludere che l'aspettativa secondo cui un CISC produce programmi più compatti, con tutti i vantaggi che ne potrebbero conseguire, può non concretizzarsi nella realtà. La seconda motivazione per l'uso di set di istruzioni sempre più complessi era poi supportata dalla convinzione che l'esecuzione delle istruzioni sarebbe risultata più veloce. In effetti, sembra abbastanza verosimile che una complessa operazione HLL possa essere eseguita più rapidamente come singola istruzione di macchina piuttosto che come una serie di istruzioni più primitive; nel primo caso, tuttavia, da un lato aumenta la complessità di tutta l'unità di controllo della CPU CISC, dall'altro aumenta la dimensione della memoria di microprogramma (Microprogram Control Store, MCS) che contiene la sequenza delle operazioni elementari della CPU con le quali viene implementata ciascuna istruzione. Entrambi questi fattori, di solito, comportano un aumento netto del tempo di esecuzione delle istruzioni semplici.
Alcuni ricercatori hanno accertato che in realtà l'incremento di velocità nell'esecuzione di funzioni complesse è dovuto non tanto alla potenza delle istruzioni complesse di macchina, quanto alla loro residenza in un Microprogram Control Store ad alta velocità [34]. In effetti, il MCS agisce come un cache di istruzioni; il progetto dell'architettura hardware parte così dall'assunto che determinate subroutine o funzioni vengono usate molto di frequente e devono quindi essere assegnate al MCS e implementate in microcodice. I risultati di questa filosofia sono stati poco incoraggianti: sui sistemi S/370, ad esempio, istruzioni come Translate ed Extended-Precision Floating Point Divide risiedono nel MCS ad alta velocità, mentre le sequenze di operazioni richieste nella fase di preparazione ad una chiamata a procedura o di inizializzazione di una routine di servizio interrupt risiedono sempre in memoria centrale, che è significativamente più lenta del MCS.
In tal modo, non è affatto chiaro che la tendenza verso set di istruzioni sempre più complessi conduca ad una esecuzione più efficiente dei programmi HLL. Questa conclusione ha spinto diversi gruppi di ricercatori ad esplorare le implicazioni di una filosofia di segno opposto.
Per quanto differenti siano stati gli approcci presi in considerazione nella definizione delle architetture RISC, essi mantengono tuttavia delle caratteristiche comuni, che sono elencate nella Tav. VI e vengono descritte nel seguito.
| Una istruzione per ciclo |
| Operazioni registro-registro |
| Modi semplici di indirizzamento |
| Formati semplici delle istruzioni |
Il primo criterio elencato in Tav. VI impone che ogni istruzione di macchina venga eseguita in un singolo ciclo di macchina. Il ciclo di macchina è definito come il tempo necessario per estrarre due operandi da altrettanti registri, eseguire un'operazione logico- aritmetica su di essi, e memorizzare il risultato in un altro registro. Le istruzioni RISC, in altri termini, non devono essere più complicate delle microistruzioni di una macchina CISC, e devono essere eseguite in tempi altrettanto brevi. Scompare a questo punto in maniera pressoché completa la necessità del microcodice: le istruzioni di macchina possono essere cablate, cioè implementate puramente in hardware, diventando così anche più veloci delle corrispondenti istruzioni su altre macchine.
Una seconda caratteristica comune prevede che la maggior parte delle operazioni siano del tipo registro-registro, e che siano disponibili soltando semplici operazioni di load e store per l'accesso alla memoria; questi criteri di progetto conducono ad una notevolissima semplificazione sia del set d'istruzioni che dell'intera unità di controllo della CPU. Ad esempio, il set di istruzioni per una CPU RISC può comprendere una o due istruzioni di addizione (ad esempio, l'addizione tra interi con e senza riporto); in contrapposizione, il VAX-11 ha 25 differenti istruzioni di addizione. Un ulteriore beneficio deriva dal fatto che un'architettura siffatta incoraggia l'ottimizzazione dell'uso dei registri, con la conseguenza che gli operandi utilizzati di frequente rimangono in una memoria ad altissima velocità.
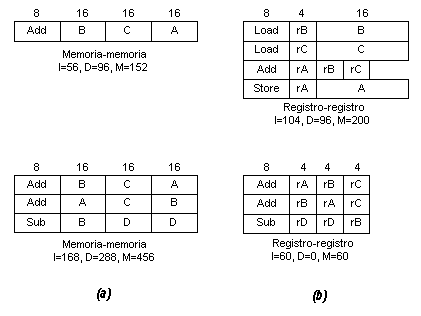
La considerevole importanza assegnata alle operazioni di tipo registro- registro è tipica del progetto delle macchine RISC. Altre macchine contemporanee dispongono ovviamente di istruzioni analoghe, ma prevedono anche operazioni memoria-memoria e operazioni registro-memoria. Già negli anni '70, ancor prima dell'apparizione dei RISC, si era tentato di confrontare tra loro queste due filosofie [29] in base al criterio illustrato in Fig. 6a; alcune architetture ipotetiche venivano valutate sia sotto l'aspetto della dimensione dei programmi sia sotto quello del numero di bit implicati nel trasferimento di informazioni tra la CPU e la memoria. Risultati come quello citato portarono un ricercatore addirittura a suggerire che le architetture future non avrebbero dovuto contenere alcun registro [26]! In realtà, quel che mancava a questi studi era la consapevolezza che un programma richiede accesso frequente solo ad un piccolo numero di scalari locali e che, disponendo di un esteso banco di registri e di un compilatore ottimizzante, la maggior parte degli operandi può rimanere memorizzata nei registri per lunghi periodi di tempo. Con questi assunti, allora, la Fig. 6b presenta una più realistica comparazione.
|
||
|
Ritornando alla Tav. VI, una terza caratteristica comune ai progetti RISC riguarda l'uso di modi semplici di indirizzamento. Quasi tutte le istruzioni RISC prevedono solo un semplice indirizzamento di registri; possono poi essere previsti diversi altri modi di indirizzamento, quali ad esempio quello tramite displacement e quello relativo al Program Counter. Altri modi ancora più complessi modi possono infine essere sintetizzati in software a partire da quelli semplici. Ancora una volta, come è facile rendersi conto, questa caratteristica di progetto semplifica in maniera significativa sia il set di istruzioni che l'unità di controllo della CPU.
Un'ultima caratteristica comune è l'uso di formati molto semplici per le istruzioni. La lunghezza dell'istruzione è prefissata ed è sempre un multiplo della lunghezza della parola di macchina, mentre la posizione dei vari campi, in particolare del codice operativo, è fissa. Questa metodologia di progetto comporta diversi benefici: con i campi fissi, la decodifica del codice operativo e l'accesso agli operandi residenti nei registri possono avvenire contemporaneamente; la semplicità dei formati si riflette in una semplificazione dell'unità di controllo; il fetch delle istruzioni, infine, risulta ottimizzato poiché vengono estratte dalla memoria unità lunghe quanto una parola di macchina.
I benefici dell'approccio RISC, che vanno determinati considerando nel loro insieme tutte le caratteristiche di progetto esaminate sopra, ricadono essenzialmente in due grandi categorie: le prestazioni e la possibilità di implementazione con circuiti VLSI.
Per quanto riguarda le prestazioni, possiamo considerare un certo numero di circostanze sufficientemente evidenti. In primo luogo, la potenziale fattibilità di compilatori ottimizzanti sempre più efficienti comporta che, avendo a disposizione istruzioni di macchina piuttosto primitive, vi sono maggiori opportunità per spostare istruzioni o gruppi di istruzioni fuori dai loop, per riorganizzare il codice allo scopo di conseguire una maggiore efficienza di esecuzione, per massimizzare l'utilizzazione dei registri, e così via. Diventa anche possibile calcolare parti significative di istruzioni complesse al momento della compilazione. Ad esempio, l'istruzione Move Characters (MVC) nell'IBM S/370 copia una stringa di caratteri da una locazione all'altra. Ogni volta che l'operazione viene eseguita, i dettagli della sua esecuzione dipendono dalla lunghezza della stringa, dall'entità e dalla direzione della sovrapposizione (overlap) delle aree sorgente e destinazione, nonché dalle caratteristiche di allineamento (al byte, alla word, etc.) delle aree stesse. In una grande quantità di casi, queste informazioni sono già note al tempo di compilazione, e il compilatore potrebbe dunque produrre una sequenza ottimizzata di istruzioni primitive per funzioni del genere.
Un secondo punto, già sottolineato in precedenza, è che la maggior parte delle istruzioni generate dal compilatore sono comunque relativamente semplici: sembra allora ragionevole ipotizzare che un'unità di controllo costruita specificamente per queste istruzioni, che faccia poco o nessun ricorso al microcodice, possa eseguirle con velocità significativamente più alta che non una macchina CISC paragonabile.
Un terzo punto è legato all'uso del pipeline delle istruzioni: i ricercatori nell'area RISC hanno in genere la convinzione che la tecnica del pipeline delle istruzioni possa essere applicata molto più efficacemente in una CPU dotata di un set ridotto di istruzioni. Esamineremo tra breve questo punto con maggiori dettagli.
Un punto finale, apparentemente meno significativo dei precedenti ma che può assumere importanza essenziale nei sistemi in tempo reale, è che i programmi RISC dovrebbero rispondere agli interrupt con maggiore rapidità, poiché il tempo di latenza di un interrupt è condizionato dalla durata di operazioni piuttosto semplici, e che sarà quindi prevedibilmente molto breve. Viceversa, le architetture con istruzioni complesse ammettono il servizio di un interrupt solo alla fine di un'istruzione; in alternativa, devono prevedere dei punti interrompibili specifici all'interno dell'istruzione ed implementare opportuni meccanismi per rendere possibile la riesecuzione di un'istruzione interrotta.
Come accennato in precedenza, la tesi relativa alle maggiori prestazioni di un'architettura con set ridotto di istruzioni è ancora ben lontana dall'essere pienamente dimostrata. In realtà, gli studi comparativi disponibili hano avuto come oggetto macchine non paragonabili tra loro né per tecnologia né per potenza; in pochissimi di essi, per di più, si è potuto o voluto separare gli effetti dovuti al set ridotto di istruzioni da quelli dovuti ad un esteso set di registri.
La seconda area di potenziali benefici dell'approccio RISC, quella legata all'implementazione VLSI, è peraltro molto più chiaramente definita. Quando si fa ricorso alle tecnologie VLSI, il progetto e l'implementazione di una CPU cambiano radicalmente. Le CPU tradizionali, come quelle dell'IBM S/370 e del VAX-11, sono costituite da una o più schede a circuito stampato contenenti componenti standard SSI o MSI; con l'avvento delle tecnologie LSI e VLSI è divenuto possibile realizzare un'intera CPU su un unico chip di silicio. Nella definizione di una CPU su singolo chip si possono individuare due motivazioni per seguire una strategia RISC.
In primo luogo, vi è il problema delle prestazioni. Dal momento che i ritardi di propagazione dei segnali elettrici all'interno di un chip sono molto più piccoli che non tra un chip e l'altro, diventa molto vantaggioso comprimere in piccole aree di silicio quelle attività che avvengono molto di frequente, ad esempio -- come abbiamo già visto -- le istruzioni semplici e l'accesso agli scalari locali. I chip del Berkeley RISC sono stati progettati, di fatto, con in mente queste considerazioni: mentre in un tipico microprocessore su singolo chip circa la metà del silicio è dedicata al microcodice di controllo, nel chip RISC I soltanto il 6% circa del silicio è dedicato all'unità di controllo [39].
Un secondo argomento legato alla tecnologia VLSI è il tempo di progetto e di implementazione. Un processore VLSI è alquanto difficile da sviluppare: invece di utilizzare componenti SSI/MSI già esistenti, il progettista deve elaborare la struttura del circuito e determinare la disposizione dei vari componenti, quindi modellare e valutare l'intero progetto a livello di dispositivo. Con un'architettura a set ridotto di istruzioni, questo processo è di gran lunga più semplice, come viene evidenziato nella Tav. VII; se poi, in aggiunta a tutto questo, le prestazioni di un RISC sono equivalenti a quelle di un microprocessore CISC confrontabile, allora i vantaggi dell'approccio RISC diventano senz'altro evidenti.
|
|||||||
© 1997-2003 Paolo Marincola (Rome, Italy)
e-mail: pmaNOSPAM@acm.org (eliminare
i caratteri "NOSPAM" per ottenere l'indirizzo esatto)
Commenti, osservazioni e suggerimenti sono estremamente graditi.
Last revised: 2003-12-06 19:47